
10. März 2025 (letzte Aktualisierung am 12. März 2025)
Dieser Artikel beschreibt meine Erfahrungen als Hobby-Programmierer mit Grundkenntnissen in Python, der ein durchaus anspruchsvolles Programm entwickelt hat. Dabei teile ich, was ich gelernt habe – insbesondere, wie man effektiv mit einem Chatbot, also einer Künstlichen Intelligenz als Sprachmodell, kommuniziert, um das gewünschte Ergebnis zu erzielen. Für das Projekt nutzte ich die kostenlosen Versionen von Grok 3 und Claude 3.7 Sonnet. Es handelt sich um eine mit Python 3 programmierte telefonische Zeitansage für die Telefonsoftware Asterisk, wobei die Sprachausgabe mithilfe von Google Text-to-Speech (gTTS) generiert wurde.
Das Skript in der vorläufig letzen Fassung vom 12. März 2025 in einer Zip mit einer ausführlichen Anleitung und allen notwendigen Sounddateien: Speaking Clock 12.3.2025.zip
Entwicklungsumgebung: Für die Programmierung mit Python sollte man auf jeden Fall Linux, genauer gesagt ein Linux auf der Basis von Debian verwenden. Auf Windows ginge es auch, aber auf Ubuntu zum Beispiel ist der Zeitaufwand geringer. Wenn man zudem noch mit der Telefonsoftware Asterisk arbeitet, ist es ein großer Vorteil, dass man problemlos Asterisk auf seinem Ubuntu laufen lassen kann. Auf Windows 10 und höher geht das jedenfalls nicht. Ich verwende Ubuntu Mate. Welches Linux man einsetzen möchte, ist mehr oder weniger eine Frage des Geschmacks und der Gewöhnung. Man ist auf der sicheren Seite, wenn man zu einer akutellen Distribution greift, die eine breite Unterstützung findet und ein hohe Verbreitung besitzt. Chatbots können einem bei der Auswahl und der Einrichtung helfen.

Stärken und Schwächen von Chatbots auf Grund von Sprachmodellen: Chatbots (Künstliche Intelligenz oder kurz KI) sind sehr gut im Coding und können auf ein umfangreiches Wissen schnell zugreifen. Sie sind echte Nerds. Sie arbeiten vor allen Dingen sehr schnell und sind unermüdlich in ihrer Hilfsbereitschaft, werden nie müde, gereizt oder genervt und sind immer freundlich.
Aber sie haben jedenfalls jetzt noch einige Schwächen. Sie sind weltfremd und können sich schlecht in die Lage eines Menschen hineinversetzen und deshalb muss man ihnen alles genau und unmissverständlich erklären. Am besten redundant und mit Beispiel. Dazu muss man den gewünschten Programmablauf kennen und was die einzelnen Programmblöcke können. Wie die einzelnen Zeilen zu programmieren sind, braucht man eigentlich nicht mehr wissen. Chatbots können auch nicht kreativ und übergreifend denken. Sie haben auch nicht diese Geistesblitze, die wir in einem entspannten Moment bekommen, nachdem wir tagelang ein Problem gewälzt haben.
Eine leicht verständliche und unterhaltsame Einführung wie Chatbots in Sprachmodellen funktionieren, warum sie manchmal reinen Blödsinn von sich geben und überraschend leistungsfähig sind. Der ganze Kanal ist zu empfehlen, um zu verstehen, wie sich das Denken von Chatbots im Vergleich zum menschlichen Denken unterscheidet. Jedenfalls hat es selbst die Entwickler der Sprachmodelle überrascht, wie leistungsfähig diese Modelle funktionieren.
Natürlich braucht man Grundkenntnisse im Coding, um die Programmstruktur verstehen zu können und um Tippfehler der KI zu finden, was auch ab und zu vorkommt. Aber die konzentrierte Tätigkeit des Codings wird einem abgenommen. Das spart sehr viel Zeit und damit auch Kosten, wenn man beruflich programmiert. Beim Coding brauchen wir keine Ahnung mehr von der Maschinensprache haben, die dahinter steckt und wir müssen auch nicht verstehen, wie die einzelnen Bibliotheken funktionieren, die wir einsetzen. Wenn wir effizient programmieren wollen, müssen wir wissen, welche Bibliotheken es gibt. Der Einsatz von Chatbots ist der logische nächste Schritt in dieser Entwicklung. Die Frage ist, ob wir dabei verblöden. Das kommt darauf an, wie wir die Künstliche Intelligenz nutzen, ob wir also unsere Zeit mit Albernheiten vertrödeln oder ob wir beharrlich ein klares Ziel verfolgen und bereit sind mit Rückschlägen konstruktiv umzugehen. So war es auch schon immer im wirklichen Leben. Man wächst mit den Aufgaben. Und jetzt bekommen wir Unterstützung durch Chatbots.
Das fertige Produkt: Eine telefonische Zeitansage mit einem Python-AGI-Skript für die Asterisk Telefonsoftware im Vergleich zur Anzeige einer über 20 Jahre alten selbst gebauten DCF77-Funkuhr . Die Schwierigkeit bestand darin die zeitverzögerte Ansage zu minimieren. Das Video zeigt, was beim Aufruf der telefonischen Zeitansage alles passiert. Die von Google gTTS erzeugten Sprachdateien werden erzeugt und nach ihrem Abspielen wieder gelöscht. In der Asterisk-Konsole lässt sich verfolgen, welche Sprachdateien gerade abgespielt werden. Schließlich ein Vergleich zwischen einer DCF77-Funkuhr und der Zeitansage, die im Abstand von 15 Sekunden erfolgt.
Vorstellung einer historischen Maschine (Zeitansagegerät Magnetton) auf elektromechanischer Basis zur Erzeugung der telefonischen Zeitansage. Die Zeiten ändern sich.
Der Werdegang des Projekts: Im ersten Schritt wurde ein unabhängiges Pythonskript geschrieben, dass als „Talking Clock“ oder „Sprechende Uhr“ alle 15 Sekunden die Zeit ansagt, wobei die Sprachdateien mit Google gTTS erzeugt werden. Für diese API braucht es keine Registrierung. Aber es gab eine Zeitverzögerung, weil das Verschicken des Textes zu Google und das Warten auf die Sprachdateien einige Sekunden dauert, weshalb die Uhrzeit einige Sekunden zu spät die Zeit aufsagte.
Die Entwicklung dieser „Sprechenden Uhr“ ist hier festgehalten:
— https://grok.com/share/bGVnYWN5_d9f89aab-dd5c-4ac7-a90d-d164682e5d76
Oft kann es vorkommen, dass sich ein Chatbot in eine Sackgasse verrennt, um mit immer komplizierteren Maßnahmen eine Lösung zu verzwingen, die weitere Probleme mit sich führen, weshalb es sinnvoll sein kann entweder von vorne anzufangen mit einem neu geschriebenen Prompt (Erörterung der Aufgabe und des Problems) oder dass man das Zwischenergebnis de Konkurrenz vorstellt und die bisherigen Erfahrungen bereitstellt. Deshalb bin ich dann ab einem bestimmten Punkt von Grok 3 zu Claude gewechselt:
— https://claude.ai/share/0b6d2396-2170-4b61-a04a-ee3c5167c114
Claude 3.7 ist bei Programmierern sehr beliebt. Es hat eine sehr praktische Oberfläche. Das Arbeiten mit der kostenlosen Version macht aber keinen besonderen Spaß, da Pausen eingebaut sind. Oder man muss ein neues Thema starten, um weitermachen zu können.
Bei der Entwicklung schlug der Chatbot immer wieder Verbesserungen vor, die auch einer einfachen Entwicklungsumgebung testete. Zum Einsatz dafür kam Thonny:
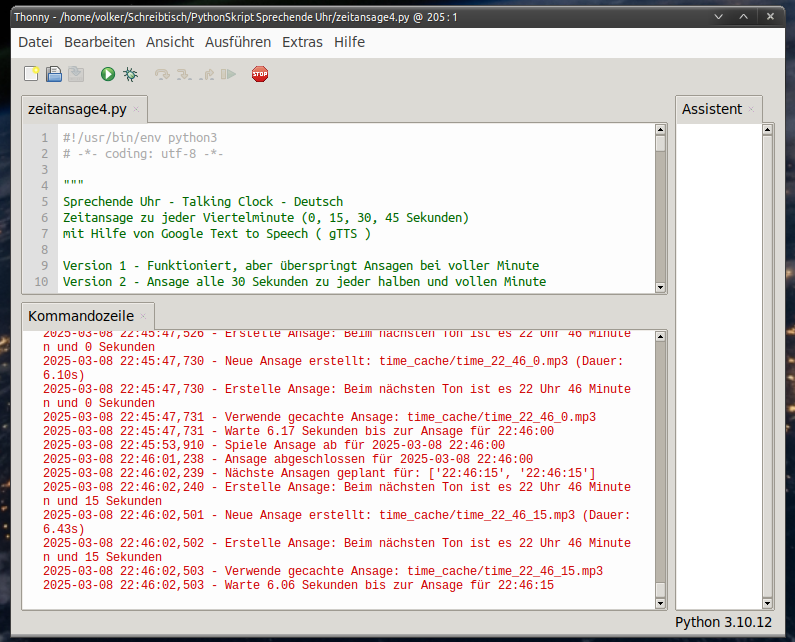
Die Fehlermeldungen, die Thonny liefert, können dem Chatbot übergeben werden, der sich dann um das Problem kümmert und dann mehr oder weniger sinnvolle Lösungen findet.
Mit der Eingabeaufforderung (Terminal) von Linux geht es auch. Allerdings lassen sich Fehlermeldungen und Rückmeldungen nicht so bequem kopieren:
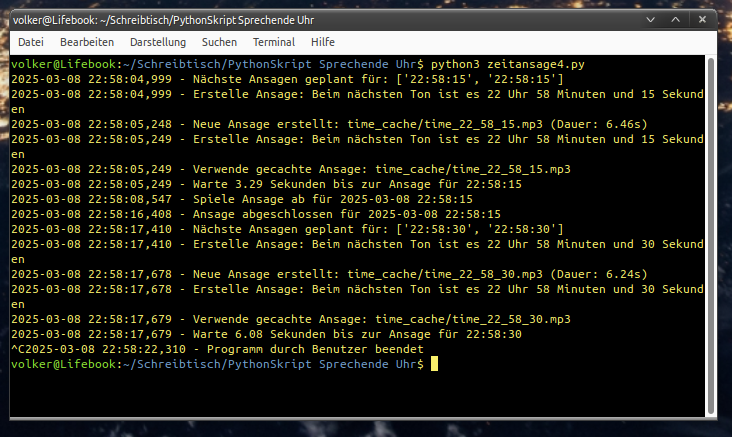
Das Hauptproblem bei der Entwicklung war die Lösung der Timingprobleme, weil die Uhrzeit immer 6 bis 7 Sekunden zu spät angesagt wurde. Google gTTS braucht Zeit um die empfangenen Texte zu MP3-Dateien umzuwandeln, die dann verschickt werden müssen. Das Problem wurde dadurch gelöst, dass die MP3-Dateien im voraus produziert werden und in einem Cache vorübergehend gespeichert werden. Das hat dann geklappt.
Hier das Skript der sprechenden Uhr, dass die Ansagen über die Soundkarte ausgibt:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Sprechende Uhr - Talking Clock - Deutsch
Zeitansage zu jeder Viertelminute (0, 15, 30, 45 Sekunden)
mit Hilfe von Google Text to Speech ( gTTS )
Wenn du das Programm im Terminal mit python3 zeitansage4.py startest,
dann musst du es mit im Terminal mit Strg+C beenden.
Version 1 - Funktioniert, aber überspringt Ansagen bei voller Minute
Version 2 - Ansage alle 30 Sekunden zu jeder halben und vollen Minute
Version 3 - Kommentarzeilen hinzugefügt
Aktuell Version 4 - Modifiziert für präzise Ansagen alle 15 Sekunden (0, 15, 30, 45)
und ein "time_cache" für die rechtzeitige Erzeugung der Ansagen
https://claude.ai/share/0b6d2396-2170-4b61-a04a-ee3c5167c114
Volker Lange-Janson 8. März 2025 / Modifiziert am 8. März 2025
Meinerseits darf jeder mit dem Skript machen, was er will.
Weitere Erklärungen nach dem Ende des Skripts
Das Skript benötigt Bibliotheken, sie unten im Text.
Das Skript braucht eine Internetverbindung für Google gTTS
zur Erzeugung der Sprache
Falls die tone.mp3 fehlt, kann sie mit Audacity erstellt
werden. 440 Hz Sinus, eine Sekunde lang, mono.
Die tone.mp3 im selben Ordner wie dieses Skript unterbringen.
"""
import datetime
from gtts import gTTS
from mutagen.mp3 import MP3
from playsound import playsound
import time
import os
import logging
import math
# Logging konfigurieren
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s')
logger = logging.getLogger(__name__)
# Konstanten
INTERVALS = [0, 15, 30, 45] # Die Sekunden, zu denen die Zeit angesagt werden soll
CACHE_DIR = "time_cache" # Verzeichnis für gecachte Zeitansagen
def setup():
"""Initialisiert das System und erstellt notwendige Verzeichnisse."""
# Stelle sicher, dass die Tone-Datei existiert
if not os.path.exists("tone.mp3"):
raise FileNotFoundError("Die Datei 'tone.mp3' wurde nicht gefunden. Bitte erstellen Sie eine MP3-Datei mit einem Piepton von ca. 1 Sekunde.")
# Cache-Verzeichnis für Zeitansagen erstellen
if not os.path.exists(CACHE_DIR):
os.makedirs(CACHE_DIR)
logger.info(f"Cache-Verzeichnis '{CACHE_DIR}' erstellt")
def get_next_announcement_times():
"""Berechnet die Zeiten für die nächsten Ansagen im 15-Sekunden-Takt."""
now = datetime.datetime.now()
result = []
# Aktuelle Minute berechnen (oder nächste Minute, wenn wir kurz davor sind)
current_minute = now.replace(second=0, microsecond=0)
if now.second >= 45 and now.microsecond > 500000: # Wenn wir kurz vor der nächsten Minute sind
current_minute += datetime.timedelta(minutes=1)
# Die nächsten 4 Ansagezeiten berechnen (für 0, 15, 30 und 45 Sekunden)
for i in range(4):
for seconds in INTERVALS:
announcement_time = current_minute.replace(second=seconds)
if announcement_time > now:
result.append(announcement_time)
# Nach Zeit sortieren und die nächsten 2 Ansagen zurückgeben
result.sort()
return result[:2] # Wir bereiten die nächsten zwei Ansagen vor
def generate_time_str(tone_time):
"""Erzeugt den Text für die Zeitansage."""
hour = tone_time.hour
minute = tone_time.minute
second = tone_time.second
# Korrekte Singular/Plural-Form
second_str = "1 Sekunde" if second == 1 else f"{second} Sekunden"
minute_str = "1 Minute" if minute == 1 else f"{minute} Minuten"
return f"Beim nächsten Ton ist es {hour} Uhr {minute_str} und {second_str}"
def get_cached_announcement(time_obj):
"""Prüft, ob eine Zeitansage bereits im Cache existiert."""
cache_filename = f"{CACHE_DIR}/time_{time_obj.hour}_{time_obj.minute}_{time_obj.second}.mp3"
if os.path.exists(cache_filename):
mp3_file = MP3(cache_filename)
return mp3_file.info.length, cache_filename
return None, None
def create_announcement(time_obj):
"""Erstellt eine MP3-Datei für die Zeitansage und gibt die Dauer zurück."""
time_str = generate_time_str(time_obj)
logger.info(f"Erstelle Ansage: {time_str}")
# Prüfen, ob die Ansage bereits im Cache ist
duration, cache_file = get_cached_announcement(time_obj)
if duration and cache_file:
logger.info(f"Verwende gecachte Ansage: {cache_file}")
return duration, cache_file
# Neue Ansage erstellen und cachen
cache_filename = f"{CACHE_DIR}/time_{time_obj.hour}_{time_obj.minute}_{time_obj.second}.mp3"
audio = gTTS(text=time_str, lang='de', slow=False)
audio.save(cache_filename)
mp3_file = MP3(cache_filename)
logger.info(f"Neue Ansage erstellt: {cache_filename} (Dauer: {mp3_file.info.length:.2f}s)")
return mp3_file.info.length, cache_filename
def prepare_announcements(announcement_times):
"""Bereitet die Zeitansagen vor und gibt eine Liste von (Zeit, Dauer, Datei) zurück."""
prepared = []
for time_obj in announcement_times:
duration, audio_file = create_announcement(time_obj)
prepared.append((time_obj, duration, audio_file))
return prepared
def play_announcement(announcement_time, announcement_file):
"""Spielt die Zeitansage und den Ton ab."""
try:
logger.info(f"Spiele Ansage ab für {announcement_time}")
playsound(announcement_file)
playsound("tone.mp3")
logger.info(f"Ansage abgeschlossen für {announcement_time}")
return True
except Exception as e:
logger.error(f"Fehler beim Abspielen: {e}")
return False
def main():
"""Hauptfunktion."""
try:
setup()
while True:
# Die nächsten Zeitansagen vorbereiten
next_announcements = get_next_announcement_times()
logger.info(f"Nächste Ansagen geplant für: {[t.strftime('%H:%M:%S') for t in next_announcements]}")
# Vorbereiten der Ansagen (generiert MP3-Dateien im Voraus)
prepared_announcements = prepare_announcements(next_announcements)
# Für jede vorbereitete Ansage
for announcement_time, duration, audio_file in prepared_announcements:
# Berechnen, wann die Ansage starten muss
start_time = announcement_time - datetime.timedelta(seconds=duration)
now = datetime.datetime.now()
# Warten bis zur Startzeit der Ansage
wait_seconds = (start_time - now).total_seconds()
if wait_seconds > 0:
logger.info(f"Warte {wait_seconds:.2f} Sekunden bis zur Ansage für {announcement_time.strftime('%H:%M:%S')}")
time.sleep(wait_seconds)
# Ansage abspielen
play_announcement(announcement_time, audio_file)
# Kleine Pause, um sicherzustellen, dass die nächste Berechnung nach der aktuellen Ansage beginnt
time.sleep(1)
# Nächste Ansagen neu berechnen (falls wir sehr nah an der nächsten sind)
if datetime.datetime.now() > next_announcements[-1] - datetime.timedelta(seconds=5):
break
except KeyboardInterrupt:
logger.info("Programm durch Benutzer beendet")
except Exception as e:
logger.error(f"Unerwarteter Fehler: {e}")
raise
if __name__ == "__main__":
main()
"""
Entwicklung und Idee:
https://grok.com/share/bGVnYWN5_d9f89aab-dd5c-4ac7-a90d-d164682e5d76
https://claude.ai/share/0b6d2396-2170-4b61-a04a-ee3c5167c114
Zeitansage über die Soundkarte
Ansagen im 15-Sekunden-Takt (0, 15, 30, 45 Sekunden jeder Minute)
Die tone.mp3 (440Hz, 1 sec lang, mono) mit Audacity erzeugt und muss sich im selben Ordner befinden wie das Skript.
Verbesserungen in Version 4:
- Caching der Zeitansagen zur Reduzierung der Netzwerkanfragen an Google TTS
- Präzises Timing durch vorausschauende Berechnung
- Robustes Fehlerhandling und Logging
- Garantierte Ansagen aller 15-Sekunden-Intervalle (0, 15, 30, 45)
Bibliotheken:
Um dieses Skript auszuführen, müssen Sie die folgenden externen Bibliotheken installieren:
pip install gTTS mutagen playsound
"""
Alle notwendigen Dateien und Informationen der „Sprechenden Uhr für die Soundkarte“ zum Download: PythonSkript Sprechende Uhr.zip
In der obigen Zip-Datei ist das lauffähige Pythonskript der sprechenden Uhr für die Soundkarte. Bitte die Komentare im Skript lesen. Was man alles beachten muss, ist unter https://grok.com/share/bGVnYWN5_b236426d-baae-4a40-9897-9a073beda5b4 beschrieben. Die tone.mp3 für den Piepton ist bereits in der Zip-Datei enthalten.

Das eigentliche Drama beginnt- Weiterentwicklung der Uhr als AGI-Skript für Asterisk für die telefonische Zeitansage: Dazu muss das vorhandene Skript so umgeschrieben werden, dass es als AGI-Skript mit der Asterisk-Telefonsoftware interagieren kann. Im ersten Moment erschien das entsprechend einfach, weil ich bereits ein entsprechendes Modul dafür geschrieben hatte:
|
|
AGI-Entwicklung für Asterisk mit einem Python-Modul vereinfacht – 29.12.2024: Wenn du dich bereits mit der Telefonsoftware Asterisk auskennst und etwas Erfahrung mit Python mitbringst, hast du den perfekten Startpunkt, um AGI (Asterisk Gateway Interface) zu erkunden. In diesem Beitrag stelle ich dir mein Python-Modul `asterisk_agi.py` vor. Es ist das Herzstück für die einfache und effektive Entwicklung von AGI-Skripten und ermöglicht dir, dynamische und interaktive Funktionen in Asterisk zu integrieren. – weiter – |

Es kann für AGI-Skripte vorgefertigte Sounddateien abspielen, darauf reagieren, was der Anrufer in die Tastatur seines Telefons eingibt, Zahlen und Ziffern aufsagen und Telefonnummern anrufen.
Ich musste also das dort vorgestellte Modul, das ebenfalls ein Pythonskript ist und das Skript der Sprechenden Uhr an einen Chatbot übergeben mit der Bitte daraus ein AGI-Skript für Asterisk zu machen, das auf dieses Modul zugreift. Das hat aber hinten und vorne nicht geklappt. Laufzeitfehler zeigte nicht nur Thonny an. Als diese behoben wurden, hörte man immer noch keinen Ton im Telefon, weil das Programm die MP3-Dateien die WAV-Dateien in einem falschem Format umwandelte, die Asterisk nicht verarbeiten konnte. Das wurde behoben und einiges mehr. Thonny zeigte keine Fehler mehr an, aber die Asterisk-Konsole meldete immer, dass es die WAV-Dateien im Cache nicht findet, obwohl sie vorhanden waren:
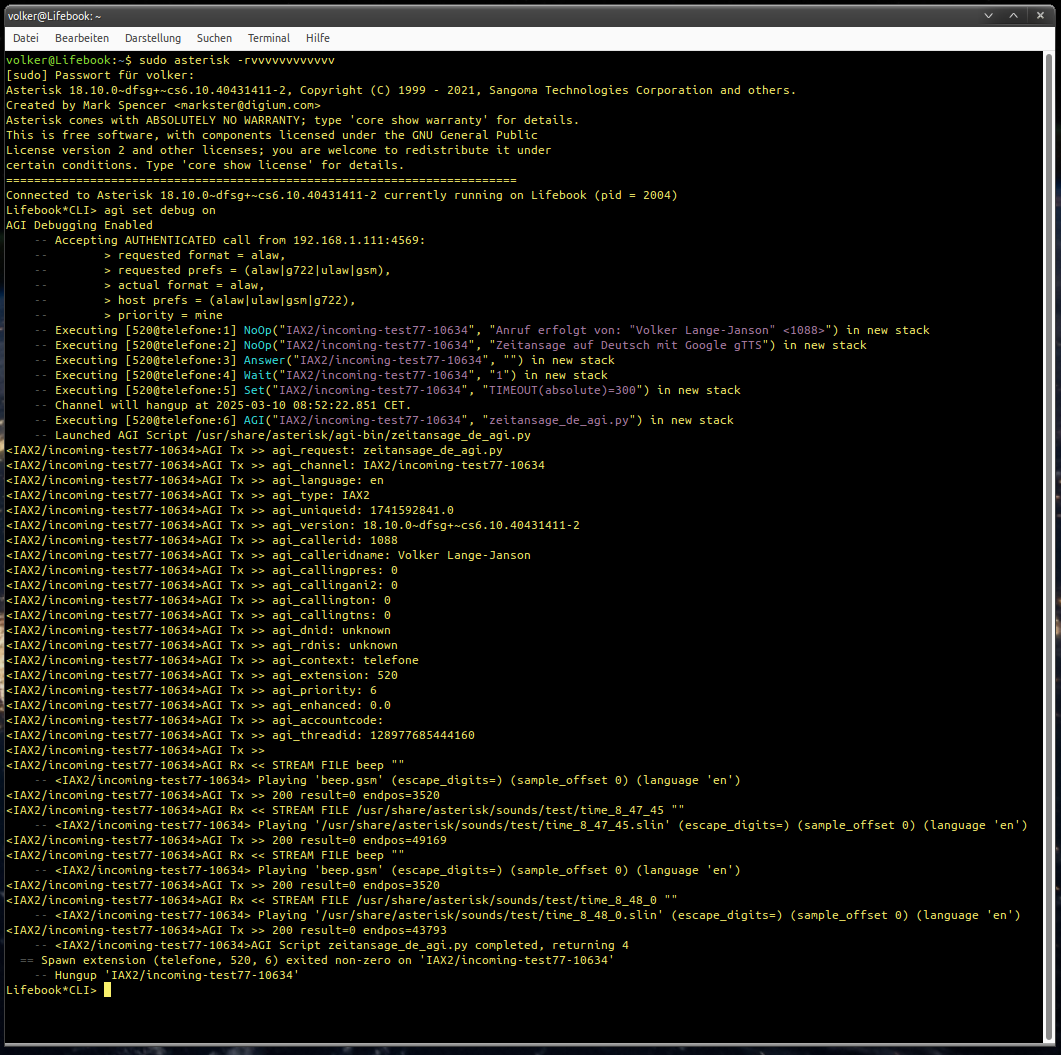
Aus unerfindlichen Gründen konnte ich keine Lösung finden. Grok 3 verhaspelte sich völlig und machte die abenteuerlichsten Lösungsvorschläge die mehr oder weniger auf dem Holzweg führten und ich gab nach einigen Stunden genervt auf. Es funktionierte alles wie es sollte. Nur konnte das AGI-Skript die Sounddateien nicht finden, was man nur in der Asterisk-Konsole feststellen konnte, wenn man „agi set debug on“ aktivierte.
Der zweite Anlauf: Nach einer Pause machte ich einen Neuanfang. Ich erinnerte mich, dass ich ein besseres Modul geschrieben hatte für AGI-Skripte:
|
|
Text-to-Speech für Asterisk: Texte mit Google gTTS in Sprache umwandeln – 10. Januar 2025: Eine neue Ansage für deine Asterisk-Telefonanlage wird gebraucht, und schon beginnt die Suche nach der passenden Datei – oder noch schlimmer, du musst sie selbst aufnehmen. Das geht viel einfacher! Mit Google Text-to-Speech (gTTS) und ein bisschen Python kannst du Texte in natürlich klingende Sprachansagen umwandeln und direkt in Asterisk nutzen. – weiter – |

Warum bin ich nicht früher darauf gekommen. Dieses Modul kann sogar Google gTTS verarbeiten. Ich bat also Grok 3 in einem erneuten Anlauf in einem neuen Thema aus diesem Modul und dem der „Sprechenden Uhr für die Soundkarte ein AGI-Skript zu machen:
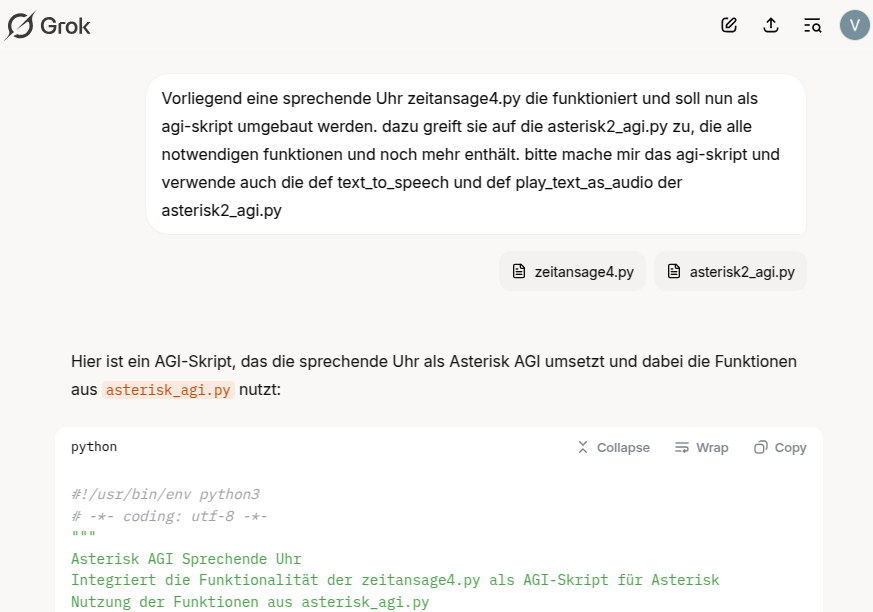
Der Werdegang lässt sich unter https://grok.com/share/bGVnYWN5_967e2923-bf19-4b4c-ac53-727acc2e1262 nachverfolgen.
Hier die wichtigsten Schritte. Meine Prompts haben Rechtschreibfehler. Aber Grok 3 stört das nicht. Hier meine Prompts, die sich schrittweise dem Problem nähern.
„kleiner fehler. das skript muss auf die asterisk2_agi.yp zugreifen, dann funktionierts. aber bitte so umbauen, dass das skript selbst in einer zeitschleife läuft für die ansagen alle 15 sekunden wie im ursprünglischen skript und du kannst den beep.gsm nehmen für den Piepton, der schon in asterisk vorhanden ist. aber das tolle ist, dass die ansage funktioniert. das hat vorher nie geklappt. also die art wie ansage erzeugt wird, umbedingt beibehalten.“
„Das Skript klappt wunderbar. Aber ein kleiner fehler. Zeitansage erfolgt im Vergleich zur meiner DCFF77-Uhr 6 Sekunden zu spät. Wäre schön, wenn man einen Parameter anpassen könnte, um diese Zeitverzögerung zu kompensieren“
„Das Funktioniert mit den 6 Sekunden verzögerung. Aber es wäre schöner, wenn genau die Ansagen für 0 15 30 und 45 sekunden kommen. müsste doch machbar sein“
„ok, sobald ein cach erzeugt wird, klappt es nicht. kann man vergessen. hatte schon vorher alles probiert. habe eine andere lösung gefunden. aber die ansage ist jetzt 7 sekunden zu früh“
„nein, das ist nicht die richtige lösung, denn dann wäre die ansage mit ungeraden zahlen. besser wäre es den beepton 7 sekunden später auszulösen“
„den future offset von 15 sekunden musst du trotzdem beibehalten“
„ok, die ansagen kommen pünktlich auf die sekunde genau, aber manchmal erst nach 30 Sekunden. Offenbar braucht die erzeugung der sounddateien zu viel zeit. deshalb bitte zeitansage nur zu jeder vollen und halben minute. bitte ändern“
Und hier mein Gedankenblitz. Erst den Beepton abspielen lassen und dann den Text generieren:
„Die Lösung. Nimm dieses Skript und rufe die beep.gsm zuerst auf und dann den Text. dann kommt der beep zur passenden zeit mit minimaler zeitverzörgerung.“
„Nein alle 15 sekunden und text so belassen wie er war. da der beep alle 15 sekunden kommt spielt das keine rolle.“
„OK, das klappt mit dem beep. Aber die Zeitansage hinkt 15 Sekunden hinterher. Das könnte man ändern in dem man die Uhrzeit durch umrechnung 15 Sekunden nach vorne schiebt. dann passt alles. auf die angesagte Uhrzeit also 15 Sekunden draufrechnen. aber darauf achten, dass es mit den stunden und minuten auch stimmt.“
„Endlich, stimmt alles auf die Sekunde genau. Das war eine harte Nuss. Aber wenn man ein Problem lösen muss, dann zahlt sich Hartnäckigkeit meistens aus. Warum bin ich nicht früher darauf gekommen, erst den beep abspielen zu lassen und dann die angekündigte Zeit 15 Sekunden nach vorne zu verschieben. Das ist die einfachste Lösung ohne Caching mit all seinen Problemen??? Und warum bist du nicht darauf gekommen? Naja, in ein paar Jahren bist du dann auch so kreativ.“
„Es kommt auf meine Webseite und jeder kann machen was er will. Ich möchte gerne, dass die asterisk2_agi.py nicht mehr benötigt wird und die notwendigen Definitions im Hauptskript integriert werden. Dann brauchen die Nutzer nur noch eine Datei für die Uhr.“
Und nun der Feinschliff:
„Das Skript läuft einwandfrei. Aber es legt alle in /usr/share/asterisk/sounds/test/ wav-dateien ab, die nicht automatisch gelöscht werden, nach dem sie abgespielt worden sind“
Blut geleckt. Jetzt will ich Versionen in Fremdsprachen haben:
„Es geht weiter. Bitte das hier
second_str = „1 Sekunde“ if second == 1 else f“{second} Sekunden“
minute_str = „1 Minute“ if minute == 1 else f“{minute} Minuten“
return f“Beim nächsten Ton ist es {hour} Uhr {minute_str} und {second_str}“
auf britisches Englisch umschreiben.“
„Bitte dieses Skript, das du kennst, auf Schwedisch modifizeren. Übrigens kommen jetzt die Soundfiles jetzt je nach Sprache in Unterordner namens de, en, sv. Warum? Wenn man gleichzeitig verschiedene Sprachen anruft, entsteht ein durcheinander, wenn alles im selben ordner.“
Und nun läuft alles wie es soll. Ich bedanke mich bei der KI. Selbstverständlich hätte ich die Prompts besser schreiben können. Die Kunst bessere Prompts zu schreiben, um schneller zum Ziel zu kommen, ist eine Frage der Übung.
Hier das AGI-Skript in seiner endgültigen Fassung:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Asterisk AGI Sprechende Uhr mit Zeitschleife
Ansagen alle 15 Sekunden (0, 15, 30, 45), Beep vor Text, Zeit 15 Sekunden vorgeschoben
Eigenständiges Skript ohne externe Abhängigkeiten außer gTTS und ffmpeg
Volker Lange-Janson, 9. März 2025
Frei verfügbar für jeden auf meiner Webseite – macht damit, was ihr wollt!
Entwicklung:
https://grok.com/share/bGVnYWN5_a13004c1-937d-47ec-ae5f-12076ca83a8b
"""
import sys
import datetime
import time
import logging
import os
from gtts import gTTS
# Logging konfigurieren
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s')
logger = logging.getLogger(__name__)
# Konstanten
INTERVALS = [0, 15, 30, 45] # Ansagen bei diesen Sekunden
TIME_SHIFT = 15 # Sekunden, um die die angekündigte Zeit vorgeschoben wird
# AGI-spezifische Funktionen
def init_env():
"""Initialisiert die AGI-Umgebung und gibt sie als Dictionary zurück."""
env = {}
while True:
line = sys.stdin.readline().strip()
if line == '':
break
key, data = line.split(':', 1)
if key[:4] != 'agi_':
sys.stderr.write("Did not work!\n")
sys.stderr.flush()
continue
key = key.strip()
data = data.strip()
if key != '':
env[key] = data
sys.stderr.write("AGI Environment Dump:\n")
sys.stderr.flush()
for key in env.keys():
sys.stderr.write(f" -- {key} = {env[key]}\n")
sys.stderr.flush()
return env
def sayit(params):
"""Spielt eine Audiodatei über Asterisk ab."""
sys.stderr.write(f"STREAM FILE {str(params)} \"\"\n")
sys.stderr.flush()
sys.stdout.write(f"STREAM FILE {str(params)} \"\"\n")
sys.stdout.flush()
result = sys.stdin.readline().strip()
return result
def text_to_speech(text, output_file="output"):
"""Konvertiert Text in Sprache und speichert ihn als WAV-Datei."""
try:
output_file = f"/usr/share/asterisk/sounds/test/{output_file}"
temp_mp3 = f"{output_file}.mp3"
temp_wav = f"{output_file}.wav"
tts = gTTS(text=text, lang="de")
tts.save(temp_mp3)
os.system(f"ffmpeg -i {temp_mp3} -ar 8000 -ac 1 -y {temp_wav}")
os.remove(temp_mp3)
sys.stderr.write(f"Text-to-Speech file saved as {temp_wav}\n")
sys.stderr.flush()
return temp_wav
except Exception as e:
sys.stderr.write(f"Error during text-to-speech conversion: {e}\n")
sys.stderr.flush()
return None
def play_text_as_audio(text, output_file="output"):
"""Konvertiert Text in Sprache, streamt ihn an Asterisk und löscht die WAV-Datei."""
wav_file = text_to_speech(text, output_file)
if wav_file:
sayit(wav_file.replace(".wav", "")) # Asterisk erwartet Pfad ohne Erweiterung
os.remove(wav_file) # WAV-Datei nach dem Abspielen löschen
sys.stderr.write(f"Deleted WAV file: {wav_file}\n")
sys.stderr.flush()
# AGI-Umgebung initialisieren
agi_env = init_env()
# Uhr-spezifische Funktionen
def generate_time_str(tone_time):
"""Erzeugt den Text für die Zeitansage mit vorgeschobener Zeit."""
shifted_time = tone_time + datetime.timedelta(seconds=TIME_SHIFT)
hour = shifted_time.hour
minute = shifted_time.minute
second = shifted_time.second
second_str = "1 Sekunde" if second == 1 else f"{second} Sekunden"
minute_str = "1 Minute" if minute == 1 else f"{minute} Minuten"
return f"Beim nächsten Ton ist es {hour} Uhr {minute_str} und {second_str}"
def play_tone():
"""Spielt den Asterisk-internen Beep-Ton ab."""
sayit("beep")
def get_next_announcement_time():
"""Berechnet die nächste Ansagezeit im 15-Sekunden-Takt."""
now = datetime.datetime.now()
current_second = now.second
current_minute = now.replace(second=0, microsecond=0)
for interval in INTERVALS:
if interval > current_second or (interval == 0 and current_second > 45):
next_time = current_minute.replace(second=interval)
if interval == 0 and current_second > 45:
next_time += datetime.timedelta(minutes=1)
return next_time
return current_minute + datetime.timedelta(minutes=1)
def announce_time(tone_time):
"""Spielt zuerst den Ton ab, dann die vorgeschobene Zeitansage."""
play_tone()
time_str = generate_time_str(tone_time)
logger.info(f"Ansage: {time_str}")
play_text_as_audio(time_str, output_file=f"time_{(tone_time + datetime.timedelta(seconds=TIME_SHIFT)).hour}_{(tone_time + datetime.timedelta(seconds=TIME_SHIFT)).minute}_{(tone_time + datetime.timedelta(seconds=TIME_SHIFT)).second}")
def main():
"""Hauptfunktion mit Zeitschleife für das AGI-Skript."""
try:
logger.info("AGI Sprechende Uhr mit Zeitschleife gestartet (Beep vor Text, Zeit +15s)")
sys.stderr.write("AGI Sprechende Uhr mit Zeitschleife gestartet (Beep vor Text, Zeit +15s)\n")
sys.stderr.flush()
while True:
next_time = get_next_announcement_time()
now = datetime.datetime.now()
wait_seconds = (next_time - now).total_seconds()
if wait_seconds > 0:
logger.info(f"Warte {wait_seconds:.2f} Sekunden bis {next_time.strftime('%H:%M:%S')}")
time.sleep(wait_seconds)
announce_time(next_time)
time.sleep(0.5)
except KeyboardInterrupt:
logger.info("Programm durch Benutzer beendet")
sys.stderr.write("Programm durch Benutzer beendet\n")
sys.stderr.flush()
except Exception as e:
logger.error(f"Fehler im AGI-Skript: {e}")
sys.stderr.write(f"Fehler im AGI-Skript: {e}\n")
sys.stderr.flush()
sys.exit(1)
if __name__ == "__main__":
main()
Folgendes ist noch zu beachten, damit das Skript läuft: https://grok.com/share/bGVnYWN5_0ed46786-78eb-4b69-a7a9-7661a151842d
Bitte beachte, dass für jede Sprache ein gesonderter Unterordner im Ordner „test“ existiert. Die Unterordner lauten
für Deutsch: de
für Englisch: en
für Schwedisch: sv
Das ist notwendig, damit kein Durcheinander mit den WAV-Dateien entsteht, wenn gleichzeitig die Zeitansage für verschiedene Sprachen angerufen wir. Das kommt zwar bei mir so gut wie nie vor, aber man sollte es gleich richtig machen.
Download AGI-Skripte „Telefonische Zeitansage“ auf Deutsch, Englisch und Schwedisch: AGI-Skripte Sprechende Uhr Sprachen en de sv.zip
Auszug aus der extensions.conf:
; Zeitansage unter der Durchwahl 520 DEUTSCH
exten => 520,1,NoOp(Anruf erfolgt von: "${CALLERID(name)}" <${CALLERID(num)}>)
same => n,NoOP(Zeitansage auf Deutsch mit Google gTTS)
same => n,Answer()
same => n,Wait(1)
same => n,Set(TIMEOUT(absolute)=300) ; Maximale Anrufdauer: 5 Minuten
same => n,AGI(zeitansage_de_agi.py)
same => n,Hangup()
; Zeitansage unter der Durchwahl 521 ENGLISCH
exten => 521,1,NoOp(Anruf erfolgt von: "${CALLERID(name)}" <${CALLERID(num)}>)
same => n,NoOP(Zeitansage auf Englisch mit Google gTTS)
same => n,Answer()
same => n,Wait(1)
same => n,Set(TIMEOUT(absolute)=300) ; Maximale Anrufdauer: 5 Minuten
same => n,AGI(zeitansage_en_agi.py)
same => n,Hangup()
; Zeitansage unter der Durchwahl 522 SCHWEDISCH
exten => 522,1,NoOp(Anruf erfolgt von: "${CALLERID(name)}" <${CALLERID(num)}>)
same => n,NoOP(Zeitansage auf Schwedisch mit Google gTTS)
same => n,Answer()
same => n,Wait(1)
same => n,Set(TIMEOUT(absolute)=300) ; Maximale Anrufdauer: 5 Minuten
same => n,AGI(zeitansage_sv_agi.py)
same => n,Hangup()
Anrufen und Ausprobieren: Wer will, kann die Nummern anrufen, wenn mein Laptop läuft, auf dem mein Testserver untergegracht ist. Man benötigt dazu Zugang zu meinem Asterisk-Server – entweder über einen SIP-Account oder über einen der angeschlossenen Telefonserver. Die Durchwahlen lauten:
Deutsche Zeitansage: 8891 520
Englische Zeitansage: 8891 521
Schwedische Zeitansage: 8891 522
Nun geht es an den Feinschliff und folgende Dinge wurden verbessert:
1. Zur Sicherheit und zur besseren Kontrolle werden Die WAV-Dateien erst 2 Sekunden nach dem Abspielen gelöscht. Dadurch hat das System mehr Zeit und der Signalton ertönt noch pünktlicher auf die Sekunde.
2. Die WAV-Datei wird erst 5 Sekunden nach dem Signalton abgespielt. Das klingt angenehmer.
3. Die WAV-Dateien werden in einem sprachspezifischen Ordner abgelegt, um Klarheit zu schaffen und gegenseitige Beeinflussungen zu vermeiden. Für die deutsche Ansage gilt der z.B. „/usr/share/asterisk/sounds/test/de/“.
4. Wenn dieselbe Nummer gleichzeitig von meheren Teilnehmern angerufen wir, werden die WAV-Dateien nicht korrekt abgespielt, weil offensichtlich eine WAV-Datei nicht von mehreren Endgerät gleichzeitig abgespielt werden kann. Der Fall kommt zwar in meinem Fall selten vor, ist aber ein Fehler. Abhilfe: Eindeutige Dateinamen mit UUID (für mehrere Anrufer). In play_text_as_audio wurde eine eindeutige ID mit uuid hinzugefügt (unique_id = str(uuid.uuid4())[:8]), sodass jede Ansage einen individuellen Dateinamen bekommt, z.B. time_12_0_15_abc123de.wav statt nur time_12_0_15.wav. Warum? Damit mehrere Anrufer gleichzeitig ihre eigene WAV-Datei haben und es keine Überschreibungen oder Konflikte gibt. Das war der Schlüssel, um das Problem mit parallelen Anrufen zu lösen. Jeder Anrufer bekommt seine eigene Datei, und alle 5 Testanrufe liefen problemlos.
Das verbesserte Skript:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Asterisk AGI Sprechende Uhr mit Zeitschleife Ansagen alle 15 Sekunden (0, 15, 30, 45), Beep vor Text, Zeit 15 Sekunden vorgeschoben Eigenständiges Skript ohne externe Abhängigkeiten außer gTTS und ffmpeg Volker Lange-Janson, 9. März 2025 Frei verfügbar für jeden auf meiner Webseite – macht damit, was ihr wollt! Entwicklung: https://grok.com/share/bGVnYWN5_a13004c1-937d-47ec-ae5f-12076ca83a8bTelefonische Zeitansage für Asterisk als Python-AGI-Skript mit Grok 3 und Claude entwickeltDamit das Skript läuft: https://grok.com/share/bGVnYWN5_0ed46786-78eb-4b69-a7a9-7661a151842d """ import sys import datetime import time import logging import os import uuid # Für eindeutige Dateinamen from gtts import gTTS # Logging konfigurieren logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s') logger = logging.getLogger(__name__) # Konstanten INTERVALS = [0, 15, 30, 45] # Ansagen bei diesen Sekunden TIME_SHIFT = 15 # Sekunden, um die die angekündigte Zeit vorgeschoben wird DELETE_DELAY = 2 # Sekunden Verzögerung vor dem Löschen der WAV-Datei WAIT_AFTER_BEEP = 5 # Warten mit der Ansage nach dem Signalton # AGI-spezifische Funktionen def init_env(): """Initialisiert die AGI-Umgebung und gibt sie als Dictionary zurück.""" env = {} while True: line = sys.stdin.readline().strip() if line == '': break key, data = line.split(':', 1) if key[:4] != 'agi_': sys.stderr.write("Did not work!\n") sys.stderr.flush() continue key = key.strip() data = data.strip() if key != '': env[key] = data sys.stderr.write("AGI Environment Dump:\n") sys.stderr.flush() for key in env.keys(): sys.stderr.write(f" -- {key} = {env[key]}\n") sys.stderr.flush() return env def sayit(params): """Spielt eine Audiodatei über Asterisk ab.""" sys.stderr.write(f"STREAM FILE {str(params)} \"\"\n") sys.stderr.flush() sys.stdout.write(f"STREAM FILE {str(params)} \"\"\n") sys.stdout.flush() result = sys.stdin.readline().strip() return result def text_to_speech(text, output_file="output"): """Konvertiert Text in Sprache und speichert ihn als WAV-Datei.""" try: output_file = f"/usr/share/asterisk/sounds/test/de/{output_file}" temp_mp3 = f"{output_file}.mp3" temp_wav = f"{output_file}.wav" tts = gTTS(text=text, lang="de") tts.save(temp_mp3) os.system(f"ffmpeg -i {temp_mp3} -ar 8000 -ac 1 -y {temp_wav}") os.remove(temp_mp3) sys.stderr.write(f"Text-to-Speech file saved as {temp_wav}\n") sys.stderr.flush() return temp_wav except Exception as e: sys.stderr.write(f"Error during text-to-speech conversion: {e}\n") sys.stderr.flush() return None def play_text_as_audio(text, output_file="output"): """Konvertiert Text in Sprache, streamt ihn an Asterisk und löscht die WAV-Datei nach Verzögerung.""" # Eindeutiger Dateiname mit UUID unique_id = str(uuid.uuid4())[:8] # Kurze eindeutige ID unique_output_file = f"{output_file}_{unique_id}" wav_file = text_to_speech(text, unique_output_file) if wav_file: time.sleep(WAIT_AFTER_BEEP) # Warten nach dem Signalton sayit(wav_file.replace(".wav", "")) # Asterisk erwartet Pfad ohne Erweiterung time.sleep(DELETE_DELAY) # 2 Sekunden warten vor dem Löschen os.remove(wav_file) # WAV-Datei nach Verzögerung löschen sys.stderr.write(f"Gelöschte WAV-Datei nach {DELETE_DELAY}s Verzögerung: {wav_file}\n") sys.stderr.flush() # AGI-Umgebung initialisieren agi_env = init_env() # Uhr-spezifische Funktionen def generate_time_str(tone_time): """Erzeugt den Text für die Zeitansage mit vorgeschobener Zeit.""" shifted_time = tone_time + datetime.timedelta(seconds=TIME_SHIFT) hour = shifted_time.hour minute = shifted_time.minute second = shifted_time.second second_str = "1 Sekunde" if second == 1 else f"{second} Sekunden" minute_str = "1 Minute" if minute == 1 else f"{minute} Minuten" return f"Beim nächsten Ton ist es {hour} Uhr {minute_str} und {second_str}" def play_tone(): """Spielt den Asterisk-internen Beep-Ton ab.""" sayit("beep") def get_next_announcement_time(): """Berechnet die nächste Ansagezeit im 15-Sekunden-Takt.""" now = datetime.datetime.now() current_second = now.second current_minute = now.replace(second=0, microsecond=0) for interval in INTERVALS: if interval > current_second or (interval == 0 and current_second > 45): next_time = current_minute.replace(second=interval) if interval == 0 and current_second > 45: next_time += datetime.timedelta(minutes=1) return next_time return current_minute + datetime.timedelta(minutes=1) def announce_time(tone_time): """Spielt zuerst den Ton ab, dann die vorgeschobene Zeitansage.""" play_tone() time_str = generate_time_str(tone_time) logger.info(f"Ansage: {time_str}") play_text_as_audio(time_str, output_file=f"time_{(tone_time + datetime.timedelta(seconds=TIME_SHIFT)).hour}_{(tone_time + datetime.timedelta(seconds=TIME_SHIFT)).minute}_{(tone_time + datetime.timedelta(seconds=TIME_SHIFT)).second}") def main(): """Hauptfunktion mit Zeitschleife für das AGI-Skript.""" try: logger.info("AGI Sprechende Uhr mit Zeitschleife gestartet (Beep vor Text, Zeit +15s)") sys.stderr.write("AGI Sprechende Uhr mit Zeitschleife gestartet (Beep vor Text, Zeit +15s)\n") sys.stderr.flush() while True: next_time = get_next_announcement_time() now = datetime.datetime.now() wait_seconds = (next_time - now).total_seconds() if wait_seconds > 0: logger.info(f"Warte {wait_seconds:.2f} Sekunden bis {next_time.strftime('%H:%M:%S')}") time.sleep(wait_seconds) announce_time(next_time) time.sleep(0.5) except KeyboardInterrupt: logger.info("Programm durch Benutzer beendet") sys.stderr.write("Programm durch Benutzer beendet\n") sys.stderr.flush() except Exception as e: logger.error(f"Fehler im AGI-Skript: {e}") sys.stderr.write(f"Fehler im AGI-Skript: {e}\n") sys.stderr.flush() sys.exit(1) if __name__ == "__main__": main()
Download dieses Skripts in einer Zip-Datei: Telefonische Zeitansage AGI-Skript 11.3.25 9Uhr16.zip

Nein, das Projekt ist immer noch nicht fertig (12. März 2025): Hier die finale Version – jedenfalls vorläufig. Störend war der Effekt, dass der Signalton etwa eine halbe Sekunde zu spät ertönt. Das Problem ist, dass man den Signalton nicht vorverlegen kann. Aber man kann stattdessen den periodisch alle 15 Sekunden auftretenden Signalton zum Beispiel um 14 Sekunden zeitverzögert abspielen lassen. Das entspricht dann einer Vorverlegung von einer Sekunde. Nach diesem Prinzip kann man eine Feinabstimmung ermöglichen. Hier das verbesserte Skript:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- """ 2025-03-12 07:30:40Telefonische Zeitansage für Asterisk als Python-AGI-Skript mit Grok 3 und Claude entwickelthttps://grok.com/share/bGVnYWN5_bc326500-1aae-47fb-8d48-7efd78d01b24 Asterisk AGI Sprechende Uhr mit Zeitschleife Ansagen alle 15 Sekunden (0, 15, 30, 45), Beep vor Text, Zeit 15 Sekunden vorgeschoben Eigenständiges Skript ohne externe Abhängigkeiten außer gTTS und ffmpeg Volker Lange-Janson, 9. März 2025 asterisk@janson-soft.de Frei verfügbar für jeden auf meiner Webseite – macht damit, was ihr wollt! So werden die Abhängigkeiten installiert: volker@Lifebook:~$ sudo apt install -y ffmpeg python3-pip && pip3 install gtts Wenn schon etwas installiert ist, kommt eine entsprechende Meldung und es wird nichts überschrieben. """ import sys import datetime import time import logging import os import uuid # Für eindeutige Dateinamen from gtts import gTTS # Logging konfigurieren logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(message)s') logger = logging.getLogger(__name__) # Konstanten INTERVALS = [0, 15, 30, 45] # Ansagen bei diesen Sekunden (originaler Zeitpunkt) BEEP_OFFSET = -0.3 # Beep in Sekunden früher TIME_SHIFT = 15 # Zeitverschiebung (15 Sekunden) DELETE_DELAY = 0 # Sekunden Verzögerung vor dem Löschen der WAV-Datei WAIT_AFTER_BEEP = 6 # Warten mit der Ansage nach dem Signalton # AGI-spezifische Funktionen def init_env(): """Initialisiert die AGI-Umgebung und gibt sie als Dictionary zurück.""" env = {} while True: line = sys.stdin.readline().strip() if line == '': break key, data = line.split(':', 1) if key[:4] != 'agi_': sys.stderr.write("Did not work!\n") sys.stderr.flush() continue key = key.strip() data = data.strip() if key != '': env[key] = data sys.stderr.write("AGI Environment Dump:\n") sys.stderr.flush() for key in env.keys(): sys.stderr.write(f" -- {key} = {env[key]}\n") sys.stderr.flush() return env def sayit(params): """Spielt eine Audiodatei über Asterisk ab.""" sys.stderr.write(f"STREAM FILE {str(params)} \"\"\n") sys.stderr.flush() sys.stdout.write(f"STREAM FILE {str(params)} \"\"\n") sys.stdout.flush() result = sys.stdin.readline().strip() return result def text_to_speech(text, output_file="output"): """Konvertiert Text in Sprache und speichert ihn als WAV-Datei.""" try: output_file = f"/usr/share/asterisk/sounds/speaking_clock_soundfiles/de/{output_file}" temp_mp3 = f"{output_file}.mp3" temp_wav = f"{output_file}.wav" tts = gTTS(text=text, lang="de") tts.save(temp_mp3) os.system(f"ffmpeg -i {temp_mp3} -ar 8000 -ac 1 -y {temp_wav}") os.remove(temp_mp3) sys.stderr.write(f"Text-to-Speech file saved as {temp_wav}\n") sys.stderr.flush() return temp_wav except Exception as e: sys.stderr.write(f"Error during text-to-speech conversion: {e}\n") sys.stderr.flush() return None def play_text_as_audio(text, output_file="output"): """Konvertiert Text in Sprache, streamt ihn an Asterisk und löscht die WAV-Datei nach Verzögerung.""" unique_id = str(uuid.uuid4())[:8] # Kurze eindeutige ID unique_output_file = f"{output_file}_{unique_id}" wav_file = text_to_speech(text, unique_output_file) if wav_file: time.sleep(WAIT_AFTER_BEEP) # Warten nach dem Signalton sayit(wav_file.replace(".wav", "")) # Asterisk erwartet Pfad ohne Erweiterung time.sleep(DELETE_DELAY) # 2 Sekunden warten vor dem Löschen os.remove(wav_file) sys.stderr.write(f"Gelöschte WAV-Datei nach {DELETE_DELAY}s Verzögerung: {wav_file}\n") sys.stderr.flush() # AGI-Umgebung initialisieren agi_env = init_env() # Uhr-spezifische Funktionen def generate_time_str(tone_time): """Erzeugt den Text für die Zeitansage mit vorgeschobener Zeit.""" shifted_time = tone_time + datetime.timedelta(seconds=TIME_SHIFT) hour = shifted_time.hour minute = shifted_time.minute second = shifted_time.second second_str = "1 Sekunde" if second == 1 else f"{second} Sekunden" minute_str = "1 Minute" if minute == 1 else f"{minute} Minuten" return f"Beim nächsten Ton ist es {hour} Uhr {minute_str} und {second_str}" def play_tone(): """Spielt den Asterisk-internen Beep-Ton ab.""" # sayit("beep") sayit("/usr/share/asterisk/sounds/speaking_clock_soundfiles/wav/tone") def get_next_announcement_time(): """Berechnet die nächste Ansagezeit im 15-Sekunden-Takt, Beep 1 Sekunde früher.""" now = datetime.datetime.now() current_second = now.second current_minute = now.replace(second=0, microsecond=0) for interval in INTERVALS: if interval > current_second or (interval == 0 and current_second > 45): next_time = current_minute.replace(second=interval) if interval == 0 and current_second > 45: next_time += datetime.timedelta(minutes=1) # Beep 1 Sekunde früher return next_time + datetime.timedelta(seconds=BEEP_OFFSET) return current_minute + datetime.timedelta(minutes=1, seconds=BEEP_OFFSET) def announce_time(tone_time): """Spielt zuerst den Ton ab, dann die vorgeschobene Zeitansage.""" play_tone() # Zeitpunkt der Ansage ist der ursprüngliche Zeitpunkt (ohne BEEP_OFFSET) original_time = tone_time - datetime.timedelta(seconds=BEEP_OFFSET) time_str = generate_time_str(original_time) logger.info(f"Ansage: {time_str}") play_text_as_audio(time_str, output_file=f"time_{(original_time + datetime.timedelta(seconds=TIME_SHIFT)).hour}_{(original_time + datetime.timedelta(seconds=TIME_SHIFT)).minute}_{(original_time + datetime.timedelta(seconds=TIME_SHIFT)).second}") def main(): """Hauptfunktion mit Zeitschleife für das AGI-Skript.""" try: logger.info("AGI Sprechende Uhr mit Zeitschleife gestartet (Beep vor Text, Zeit +15s, Beep 1s früher)") sys.stderr.write("AGI Sprechende Uhr mit Zeitschleife gestartet (Beep vor Text, Zeit +15s, Beep 1s früher)\n") sys.stderr.flush() while True: next_time = get_next_announcement_time() now = datetime.datetime.now() wait_seconds = (next_time - now).total_seconds() if wait_seconds > 0: logger.info(f"Warte {wait_seconds:.2f} Sekunden bis Beep um {next_time.strftime('%H:%M:%S')}") time.sleep(wait_seconds) announce_time(next_time) time.sleep(0.5) except KeyboardInterrupt: logger.info("Programm durch Benutzer beendet") sys.stderr.write("Programm durch Benutzer beendet\n") sys.stderr.flush() except Exception as e: logger.error(f"Fehler im AGI-Skript: {e}") sys.stderr.write(f"Fehler im AGI-Skript: {e}\n") sys.stderr.flush() sys.exit(1) if __name__ == "__main__": main()
Das neue Skript in der vorläufig letzen Fassung vom 12. März 2025 in einer Zip mit einer ausführlichen Anleitung und allen notwendigen Sounddateien: Speaking Clock 12.3.2025.zip
Nachtrag: In der Zip-Datei hat sich ein Fehler eingeschlichen: Durch den Befehl
sudo apt install -y ffmpeg python3-pip && pip3 install gtts
wird gtts nicht systemweit integriert und gtts läuft nich unter asterisk. Führe
sudo pip3 install gtts
aus und dann läuft das Skript Siehe auch https://chatgpt.com/share/68aabba2-1c3c-8013-8323-02f6f24d5fe1.
Bitte die Anleitung in der Zip sorgfältig durchlesen. Dann klappt es auch.
Die Soundfiles werden nach jedem Abspielen gelöscht. Jeder Anrufer bekommt durch eine einmalige Kennung seine eigenen Soundfiles. Dadurch kommen sich mehrere Anrufer, die gleichzeitig die Zeit abhören, nicht ins Gehege. Allerdings bleibt nach jedem Anruf ein Soundfile übrig, das etwa 100 kByte groß ist. Man könnte einen Cron Job schreiben, den entsprechenden Ordner jede Nacht zu leeren oder man macht es alle paar Monate von Hand.
Es besteht jetzt auch die Möglichkeit für den Signalton andere Soundfiles einzusetzen. Eine Alternative ist der Zip beigefügt.
Störend war auch, dass die Ansage direkt nach dem Signalton kam. Nun wurde eine einstellbare Zeitverzögerung von einigen Sekunden eingebaut. Das klingt natürlicher.
Früher ertönte der Signalton alle 10 Sekunden. Das hatte ich auch ausprobiert und führte zu Timingproblemen. Manche Ansagen wurden übersprungen. Mit 15 Sekunden Pause zwischen den Signaltönen ist man auf der sichern Seite.
Die sprechende Uhr lässt sich auch in anderen Sprachen konvertieren. Einfach die deutsche zeitansage_de_agi.py in ChatGPT, Cluade oder Grok3 hochladen mit der Bitte sie für eine andere Sprache zu konvertieren. Grok3 hat das jedenfalls gleich kapiert und die Ansage nicht nur übersetzt sondern auch ungefragt die Grammatik angepasst. Google Text to Speech gTTS beherrscht sehr viele Sprachen.
Fazit: Die telefonische Zeitansage ist ein Relikt aus einer Zeit, als die Uhren noch nicht genau gingen und das Internet noch in den Kinderschuhen steckte. Die Entwicklung dieser Zeitansage war aber ein lehrreiches Projekt, um zu zeigen, wie man mit Hilfe von Chatbots Schritt für Schritt ein praxistaugliches Ergebnis erhält. Dabei kommt es darauf die richtigen Prompts zu formulieren, damit der Chatbot sinnvolle Anweisungen erhält. Dies gelingt nur, wenn man den Programmablauf verstanden hat und die Fallstricke kennt. Ganz ohne Kenntnisse in der Programmierung und Softwareentwicklung geht es also doch nicht. Dennoch ist die Zeitersparnis beachtlich und detailierte Kenntnisse für das Coding sind nicht mehr notwendig. Das Denken verschiebt sich mehr auf Systeme und Abläufe, die man jedoch verstehen muss, um auf gute Ideen zu kommen, auf die ein Chatbot (noch nicht) kommen kann.

Ich glaube den Chatbots fehlt noch ein Denken, das aus einer Mischung von Kreativität und Logik besteht. Chatbots sind sehr gut im Erkennen und Umsetzen von Regeln, mit denen sie trainiert worden sind. Aber über den berühmten Tellerrand können sie noch nicht blicken. Da die Entwicklung erst in den Kinderschuhen steckt, kann sich das in den nächsten Jahren noch dramatisch ändern.
Ich bin zuversichtlich, dass das Projekt mit der Version vom 12. März 2025 abgeschlossen ist. Viel Spaß mit der sprechenden Uhr, Python, Asterisk und nicht zuletzt mit Linux!