
12. März 2025
Manchmal braucht man eine einfache Lösung, um Text in Sprache umzuwandeln – etwa für Ansagen in einer Telefonanlage wie Asterisk. Genau dafür habe ich ein kleines Python-Skript geschrieben, das Eingabetexte in WAV-Dateien umwandelt und dabei sogar eine hübsche grafische Oberfläche mitbringt. Es ist perfekt für alle, die schnell und unkompliziert Audiodateien erstellen möchten, ohne sich durch komplexe Software kämpfen zu müssen.
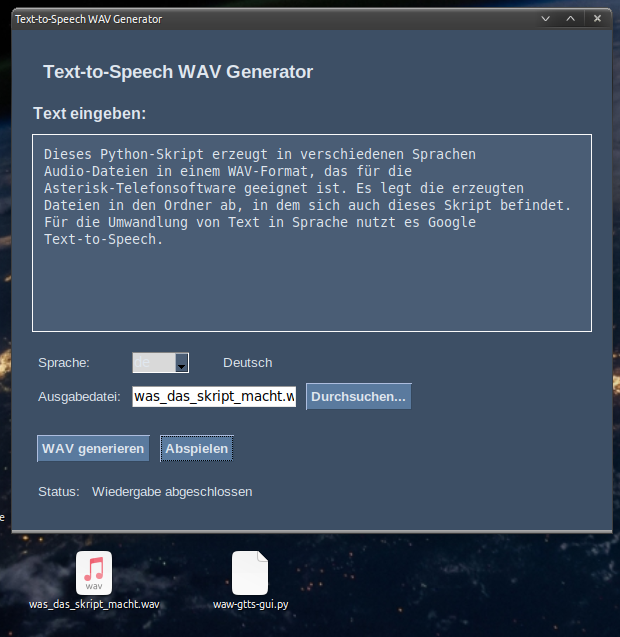
Skript zum Download in einer Zip-Datei: waw-gtts-gui.py.zip
Klangbeispiele: Google gTTS in seiner kostenlosen Versionen ist nur für kurze Sätze geeignet, da es sich sonst oft in der Betonung vergreift.
Bedienung: Das Programm selbst ist denkbar einfach zu bedienen. Nach dem Start öffnet sich ein Fenster, in dem man den gewünschten Text eingeben kann – sei es eine Begrüßung, eine Warteschleifenansage oder eine Fehlermeldung. Darunter wählt man die Sprache aus, etwa Deutsch, Englisch oder Schwedisch, und legt fest, wie die Ausgabedatei heißen soll. Mit einem Klick auf „WAV generieren“ macht sich das Skript an die Arbeit: Es nutzt die Google Text-to-Speech-Bibliothek (gTTS), um den Text in eine Audiodatei zu verwandeln. Diese wird zunächst als MP3 erstellt und dann mit Hilfe von ffmpeg in eine WAV-Datei mit Asterisk-kompatiblen Einstellungen (8 kHz, Mono) umgewandelt. Danach kann man die Datei direkt im Programm abspielen, um zu hören, ob alles passt. Der Status am unteren Rand des Fensters zeigt dabei immer an, was gerade passiert – ob die Datei generiert wird, abgespielt wird oder etwas schiefgelaufen ist.
Funktion: Technisch gesehen ist das Skript eine Kombination aus mehreren Bausteinen. Die grafische Oberfläche basiert auf tkinter, einer Standardbibliothek von Python, die mit einem blaugrauen Farbschema aufgehübscht wurde, damit sie nicht nur funktional, sondern auch ansprechend ist. Der eigentliche Text-to-Speech-Prozess läuft über gTTS, das die Google-Sprachengine im Hintergrund nutzt – eine Internetverbindung ist also nötig. Für die Konvertierung von MP3 zu WAV kommt ffmpeg ins Spiel, ein mächtiges Werkzeug, das allerdings separat installiert werden muss. Zum Abspielen der Dateien versucht das Skript zunächst, den Linux-Player „aplay“ zu verwenden, fällt bei Bedarf aber auf Alternativen wie „paplay“ oder systemeigene Player zurück. Das macht es flexibel, auch wenn es bedeutet, dass die Wiedergabe je nach Betriebssystem unterschiedlich gut funktioniert.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Text-to-Speech WAV File Generator with GUI
Generates a WAV file from input text using gTTS and plays it with aplay.
"""
from gtts import gTTS
import os
import subprocess
import tkinter as tk
from tkinter import ttk, messagebox, filedialog
# Farbschema (Blaugrautöne)
COLORS = {
"bg_dark": "#2E3B4E",
"bg_main": "#3D4F65",
"bg_light": "#4A5D75",
"text": "#E0E7EF",
"accent": "#6B8CAE",
"button": "#5A7A9E"
}
def text_to_speech(text, lang, output_file):
"""
Converts a given text to speech, saves it as a WAV file, and plays it.
Parameters:
text (str): The text to be converted to speech.
lang (str): The language code (e.g., 'de', 'en', 'sv').
output_file (str): The name of the output WAV file (e.g., 'peng.wav').
Returns:
str: The path to the generated WAV file or None in case of error.
"""
try:
temp_mp3 = "temp_output.mp3"
tts = gTTS(text=text, lang=lang)
# Save the audio as an MP3 file
tts.save(temp_mp3)
# Convert MP3 to WAV (requires ffmpeg installed)
os.system(f"ffmpeg -i {temp_mp3} -ar 8000 -ac 1 -y {output_file}")
# Cleanup MP3 file
os.remove(temp_mp3)
return output_file
except Exception as e:
messagebox.showerror("Fehler", f"Fehler bei der Umwandlung in Sprachdatei: {e}")
return None
class TTSApp:
def __init__(self, root):
self.root = root
self.root.title("Text-to-Speech WAV Generator")
self.root.geometry("600x500")
self.root.configure(bg=COLORS["bg_main"])
self.create_styles()
self.create_widgets()
# Initialisiere Standardwerte
self.language_var.set("de")
# Verwende das Verzeichnis des Skripts als Standardausgabeverzeichnis
self.output_dir = os.path.dirname(os.path.abspath(__file__))
self.output_file_var.set("output.wav")
def create_styles(self):
"""Definiert die Stile für ttk-Widgets"""
self.style = ttk.Style()
# Konfiguriere den Stil für ttk-Widgets
self.style.configure("TFrame", background=COLORS["bg_main"])
self.style.configure("TLabel",
background=COLORS["bg_main"],
foreground=COLORS["text"],
font=("Arial", 10))
self.style.configure("TButton",
background=COLORS["button"],
foreground=COLORS["text"],
font=("Arial", 10, "bold"))
self.style.configure("TCombobox",
background=COLORS["bg_light"],
fieldbackground=COLORS["bg_light"],
foreground=COLORS["text"])
self.style.map("TButton",
background=[("active", COLORS["accent"])])
# Header-Stil
self.style.configure("Header.TLabel",
font=("Arial", 14, "bold"),
padding=10)
# Abschnitt-Stil
self.style.configure("Section.TLabel",
font=("Arial", 12, "bold"),
padding=(0, 10, 0, 5))
def create_widgets(self):
"""Erstellt die GUI-Elemente"""
# Hauptframe
main_frame = ttk.Frame(self.root)
main_frame.pack(fill=tk.BOTH, expand=True, padx=20, pady=20)
# Titel
title_label = ttk.Label(main_frame, text="Text-to-Speech WAV Generator",
style="Header.TLabel")
title_label.pack(fill=tk.X)
# Text-Eingabebereich
text_section = ttk.Label(main_frame, text="Text eingeben:",
style="Section.TLabel")
text_section.pack(fill=tk.X)
self.text_frame = ttk.Frame(main_frame)
self.text_frame.pack(fill=tk.BOTH, expand=True, pady=5)
self.text_entry = tk.Text(self.text_frame,
bg=COLORS["bg_light"],
fg=COLORS["text"],
insertbackground=COLORS["text"],
relief="flat",
padx=10,
pady=10,
height=10,
wrap=tk.WORD)
self.text_entry.pack(fill=tk.BOTH, expand=True)
# Sprachauswahl
options_frame = ttk.Frame(main_frame)
options_frame.pack(fill=tk.X, pady=10)
language_label = ttk.Label(options_frame, text="Sprache:")
language_label.grid(row=0, column=0, padx=5, pady=5, sticky="w")
self.language_var = tk.StringVar()
languages = [
("Deutsch", "de"),
("Englisch", "en"),
("Schwedisch", "sv")
]
language_combo = ttk.Combobox(options_frame,
textvariable=self.language_var,
values=[lang[1] for lang in languages],
state="readonly",
width=5)
language_combo.grid(row=0, column=1, padx=5, pady=5, sticky="w")
# Anzeige der Sprachbeschreibung
self.lang_desc_var = tk.StringVar()
self.lang_desc_var.set("Deutsch")
def update_lang_desc(event):
for desc, code in languages:
if code == self.language_var.get():
self.lang_desc_var.set(desc)
break
language_combo.bind("<<ComboboxSelected>>", update_lang_desc)
lang_desc_label = ttk.Label(options_frame, textvariable=self.lang_desc_var)
lang_desc_label.grid(row=0, column=2, padx=5, pady=5, sticky="w")
# Ausgabedatei
file_label = ttk.Label(options_frame, text="Ausgabedatei:")
file_label.grid(row=1, column=0, padx=5, pady=5, sticky="w")
self.output_file_var = tk.StringVar()
output_file_entry = ttk.Entry(options_frame,
textvariable=self.output_file_var,
width=20)
output_file_entry.grid(row=1, column=1, padx=5, pady=5, sticky="w", columnspan=2)
browse_button = ttk.Button(options_frame,
text="Durchsuchen...",
command=self.browse_output_file)
browse_button.grid(row=1, column=3, padx=5, pady=5, sticky="w")
# Aktionsbereich
actions_frame = ttk.Frame(main_frame)
actions_frame.pack(fill=tk.X, pady=10)
generate_button = ttk.Button(actions_frame,
text="WAV generieren",
command=self.generate_wav)
generate_button.pack(side=tk.LEFT, padx=5)
play_button = ttk.Button(actions_frame,
text="Abspielen",
command=self.play_wav)
play_button.pack(side=tk.LEFT, padx=5)
# Status
self.status_var = tk.StringVar()
self.status_var.set("Bereit")
status_frame = ttk.Frame(main_frame)
status_frame.pack(fill=tk.X, pady=10)
status_label = ttk.Label(status_frame, text="Status:")
status_label.pack(side=tk.LEFT, padx=5)
status_text = ttk.Label(status_frame, textvariable=self.status_var)
status_text.pack(side=tk.LEFT, padx=5)
def browse_output_file(self):
"""Ermöglicht die Auswahl der Ausgabedatei"""
file_path = filedialog.asksaveasfilename(
defaultextension=".wav",
filetypes=[("WAV-Dateien", "*.wav")],
initialdir=self.output_dir,
title="WAV-Datei speichern"
)
if file_path:
self.output_dir = os.path.dirname(file_path)
self.output_file_var.set(os.path.basename(file_path))
def generate_wav(self):
"""Generiert die WAV-Datei aus dem eingegebenen Text"""
text = self.text_entry.get("1.0", tk.END).strip()
if not text:
messagebox.showwarning("Warnung", "Bitte geben Sie einen Text ein.")
return
lang = self.language_var.get()
output_file = os.path.join(self.output_dir, self.output_file_var.get())
# Stelle sicher, dass die Datei die .wav-Erweiterung hat
if not output_file.lower().endswith('.wav'):
output_file += '.wav'
self.output_file_var.set(os.path.basename(output_file))
self.status_var.set("Generiere WAV-Datei...")
self.root.update_idletasks()
result = text_to_speech(text, lang, output_file)
if result:
self.status_var.set(f"WAV-Datei gespeichert: {os.path.basename(output_file)}")
messagebox.showinfo("Erfolg", f"WAV-Datei erfolgreich generiert:\n{output_file}")
else:
self.status_var.set("Fehler bei der Generierung")
def play_wav(self):
"""Spielt die generierte WAV-Datei ab"""
output_file = os.path.join(self.output_dir, self.output_file_var.get())
if not os.path.exists(output_file):
messagebox.showwarning("Warnung",
"Die WAV-Datei existiert nicht. Bitte generieren Sie zuerst eine WAV-Datei.")
return
self.status_var.set(f"Spiele {os.path.basename(output_file)} ab...")
try:
# Versuche zuerst mit aplay
try:
subprocess.run(["aplay", output_file], check=True)
except (subprocess.CalledProcessError, FileNotFoundError):
# Wenn aplay fehlschlägt, versuche es mit paplay
try:
subprocess.run(["paplay", output_file], check=True)
except (subprocess.CalledProcessError, FileNotFoundError):
# Wenn beide fehlschlagen, versuche es mit systemspezifischem Player
if os.name == 'nt': # Windows
os.startfile(output_file)
elif os.name == 'posix': # Linux/Mac
subprocess.run(["xdg-open", output_file], check=True)
else:
raise RuntimeError("Kein geeigneter Audioplayer gefunden")
self.status_var.set(f"Wiedergabe abgeschlossen")
except Exception as e:
self.status_var.set("Fehler bei der Wiedergabe")
messagebox.showerror("Fehler", f"Fehler beim Abspielen der WAV-Datei: {e}")
if __name__ == "__main__":
root = tk.Tk()
app = TTSApp(root)
root.mainloop()
Notwendige Abhängigkeiten: Damit das Ganze läuft, gibt es ein paar Abhängigkeiten, die man bereithalten muss. Python 3 sollte ohnehin auf den meisten Systemen vorhanden sein, ebenso wie pip, um die benötigten Bibliotheken zu installieren. Mit einem einfachen Befehl wie „pip install gtts“ holt man sich die Text-to-Speech-Funktionalität ins Haus. Für die GUI ist tkinter normalerweise schon dabei, aber ffmpeg muss manuell nachinstalliert werden – unter Linux etwa über den Paketmanager („sudo apt install ffmpeg“), unter Windows oder macOS über die offizielle Webseite. Ohne ffmpeg bleibt die WAV-Konvertierung auf der Strecke, also ist das ein Muss, wenn man Asterisk-kompatible Dateien haben will. Wer die WAV-Dateien direkt abspielen möchte, sollte zudem sicherstellen, dass ein Audioplayer wie aplay oder paplay verfügbar ist – unter Windows greift das Skript auf den Standard-Mediaplayer zurück.
Dieser Linux-Befehl müsste alle Abhängigkeiten für das Programm auf einen Schlag installieren:
sudo apt-get update && sudo apt-get install -y python3-tk ffmpeg alsa-utils && pip install gtts
Fazit: Für Asterisk-Nutzer ist das Skript ein echter Gewinn. Die generierten WAV-Dateien passen perfekt zu den Anforderungen der Telefonsoftware, und man spart sich das Herumhantieren mit externen Tools oder teurer Sprachsynthese-Software. Obendrein ist es anpassbar: Wer andere Sprachen oder Formate braucht, kann den Code mit wenig Aufwand erweitern. Für mich war es eine kleine Bastelaufgabe mit großem Nutzen – und vielleicht ist es ja auch für andere ein praktischer Helfer im Telefonie-Alltag.
Ursprünglich lag das Skript auf Kommandozeilenebene vor. Von Claude 3.7 Sonnet habe ich mir die GUI machen lassen und noch um Hintergrundinformationen gebeten: https://claude.ai/share/cda22657-84ce-4ea2-8cbd-44a92c480b05. Der Text stammt von Grok3. Solche Artikel generieren kaum Werbeeinnahmen, da die Zielgruppe sehr klein ist. Deshalb muss das Texten schnell gehen.