
5. März 2026
In vielen Museen stehen sie noch – alte Telefonvermittlungen, stumm und unberührt hinter Glas. Dieses Projekt erweckt eine solche Anlage zum Leben: Besucher heben den Hörer ab, nennen einen Namen oder eine Nummer, und die Vermittlung stellt durch. Was wie Magie klingt, steckt dahinter: das quelloffene Spracherkennungsmodell Whisper von OpenAI, kombiniert mit der Telefonanlage Asterisk auf einem Raspberry Pi.
Erstellt habe ich das Skript hauptsächlich mit Claude Sonnet 4.6. Zum Einsatz kam die kostenlose Version dieser KI. Einen kleinen Teil hat die KI Gemini übernommen als ich Claude nicht erreichen konnte. Bei Rückfragen empfehle ich den Einsatz dieser beiden Sprachmodelle. Mir persönlich gefällt Claude Sonnet 4.6 besser.
Skript, Konfigurationen, Soundfiles in einer ZIP-Datei: Sprachgesteuerte Vermittlung mit Whisper und gTTS.zip
Umgebung: Fujitsu Esprimo Q520 mit 8 GB RAM und Ubuntu Mate 24.04 LTS, Python 3, Asterisk 20.6.0
Es ist sehr praktisch die Entwicklung auf einem Desktop-Rechner oder Laptop mit Ubuntu oder einem anderen Debian vorzunehmen. Der Asterisk auf diesem Rechner ist per IAX2 mit einem anderen Asterisk verbunden, der als Gateway zur Außenwelt dient. Man spart sich dadurch das Arbeiten mit Filezilla für FTPS und den SSH-Zugang. Dateien können direkt bearbeitet werden.
Wie installiert man Whisper und alle notwendigen Abhängigenkeiten für das Pythonskript? Die HTML-Datei whisper_installation gibt Auskunft darüber.

Wie das Skript whisper_vermittlung.py funktioniert: Das Skript wird von der Telefonanlage Asterisk aufgerufen, sobald ein Anrufer in der Warteschleife gesprochen hat. Asterisk nimmt die Spracheingabe als WAV-Datei auf und übergibt den Dateipfad als Parameter an das Skript. Von diesem Moment an übernimmt das Skript die vollständige Kontrolle über die Auswertung.
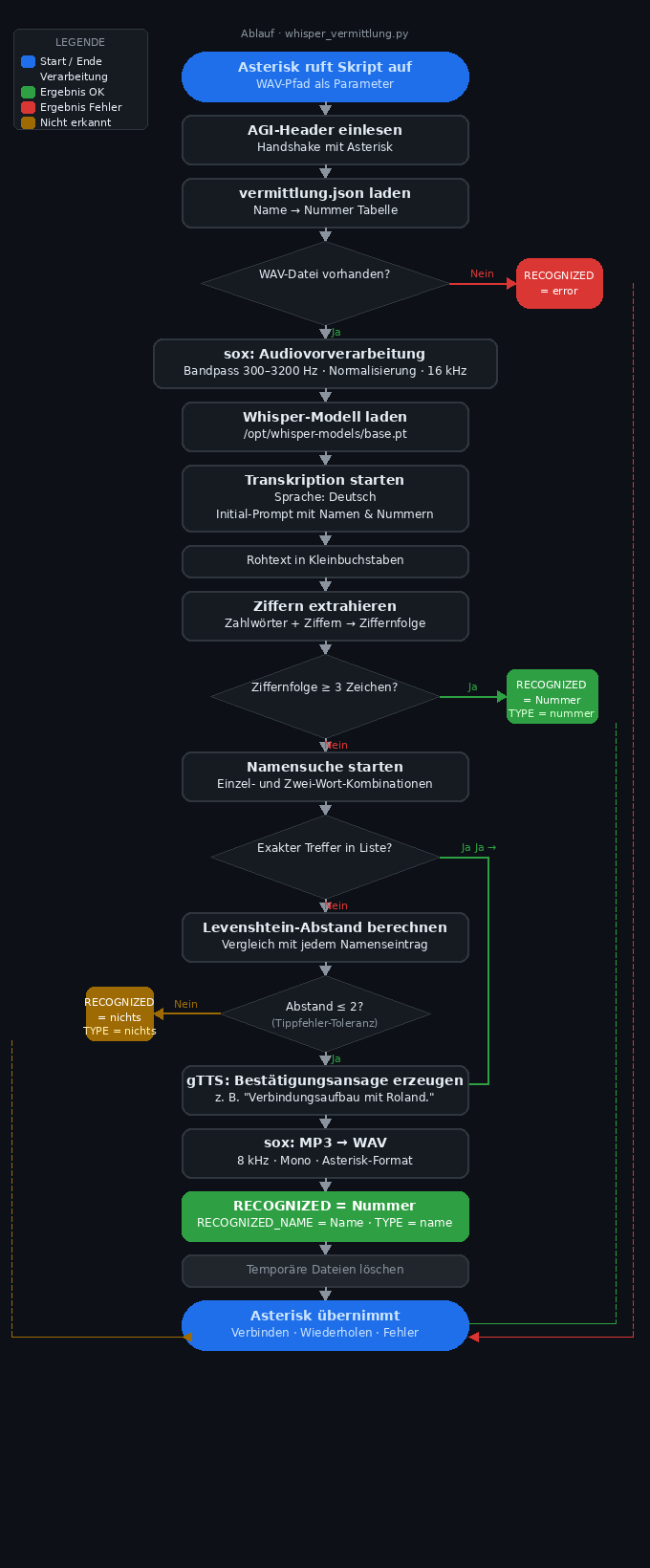
Zunächst liest das Skript die sogenannten AGI-Header ein – das ist ein technisches Handshake-Protokoll zwischen Asterisk und dem externen Programm. Diese Zeilen enthalten Informationen über den aktuellen Anruf, werden aber vom Skript nur konsumiert und nicht weiterverarbeitet. Erst danach beginnt die eigentliche Arbeit.
Als nächstes lädt das Skript die Namensliste aus der Datei vermittlung.json. Diese Datei enthält eine einfache Zuordnung: Name links, Nebenstellen-Nummer rechts. Ist die Datei nicht vorhanden oder fehlerhaft, arbeitet das Skript trotzdem weiter – die Namenserkennung entfällt dann einfach, und nur direkt gesprochene Ziffern können noch erkannt werden.
Die sprachgesteuerte Vermittlung in der Praxis. Der Anrufer möchte die „Zeitansage Deutschland“ hören und wird nach seiner Ansage mit der Nummer 119 verbunden. Die 119 war tatsächlich damals die Nummer der Zeitansage.
Bevor das Audiomaterial an Whisper übergeben wird, durchläuft die WAV-Datei eine Vorverarbeitung durch das Programm sox. Dabei wird die Audiodatei auf 16.000 Hz hochgesampelt (Whisper arbeitet intern mit dieser Abtastrate), auf einen einzigen Audiokanal reduziert und durch einen Bandpassfilter geschickt, der nur Frequenzen zwischen 300 und 3.200 Hz durchlässt. Das entspricht exakt dem Frequenzband eines analogen Telefongesprächs. Außerdem wird die Lautstärke normalisiert. Diese Vorverarbeitung verbessert die Erkennungsrate bei Telefonaudio erheblich, weil Whisper sonst auf Breitband-Sprache trainiert ist und Telefonrauschen außerhalb dieses Bandes stören kann.
Anschließend wird das Whisper-Modell geladen und die Transkription gestartet. Das Modell ist so konfiguriert, dass es ausschließlich Deutsch erkennt. Durch den Anfangs-Prompt – eine Liste aller bekannten Nummern und Namen – wird Whisper in die richtige Richtung gelenkt, sodass es Wörter wie „Roland“ oder „1004“ bevorzugt erkennt, anstatt ähnlich klingende aber bedeutungslose Alternativen zu wählen. Das Ergebnis ist ein einfacher Rohtext in Kleinbuchstaben.
Dieser Rohtext wird nun in zwei Schritten ausgewertet. Im ersten Schritt versucht das Skript, Ziffern zu extrahieren. Es durchsucht den Text Wort für Wort und übersetzt sowohl ausgeschriebene Zahlwörter („eins“, „zwei“, „drei“ usw.) als auch direkte Ziffernzeichen in eine Ziffernfolge. Hat der Anrufer also „eins null null vier“ gesagt, entsteht daraus die Zeichenkette „1004“. Wenn eine Ziffernfolge von mindestens drei Zeichen gefunden wird, gilt die Erkennung als erfolgreich, und das Skript gibt diese Nummer sofort zurück. Längere Eingaben wie Durchwahlen funktionieren auf dieselbe Weise.
Wurde keine brauchbare Ziffernfolge gefunden, startet der zweite Schritt: die Namenserkennung. Das Skript zerlegt den Rohtext in einzelne Wörter und bildet zusätzlich Zwei-Wort-Kombinationen, um auch Vor- und Nachnamen zusammen erkennen zu können. Jede dieser Kombinationen wird mit der geladenen Namensliste verglichen. Zuerst wird auf exakte Übereinstimmung geprüft. Schlägt das fehl, berechnet das Skript den sogenannten Levenshtein-Abstand – ein Maß dafür, wie viele einzelne Buchstaben-Änderungen nötig wären, um aus dem erkannten Wort den gespeicherten Namen zu machen. Ist dieser Abstand zwei oder kleiner, gilt der Name als erkannt. Das bedeutet: ein einzelner Buchstabendreher oder ein Versprecher wird toleriert, zu weit entfernte Wörter werden jedoch verworfen.
Wurde ein Name erkannt, lässt das Skript über gTTS (Google Text-to-Speech) eine kurze Bestätigungsansage erzeugen, zum Beispiel „Verbindungsaufbau mit Roland.“ Diese wird als MP3 gespeichert, von sox in das Asterisk-kompatible WAV-Format konvertiert und dann über die Telefonleitung abgespielt. So hört der Anrufer eine Rückmeldung, bevor er durchgestellt wird.
Am Ende übergibt das Skript das Ergebnis als Asterisk-Variable namens RECOGNIZED zurück an die Telefonanlage. Enthält diese Variable eine Nummer, stellt Asterisk die Verbindung her. Enthält sie „nichts“, weiß Asterisk, dass die Erkennung gescheitert ist, und kann den Anrufer um eine Wiederholung bitten. Bei einem technischen Fehler enthält sie „error“, was eine eigene Fehlerbehandlung auslösen kann.
Temporäre Audiodateien werden am Ende automatisch gelöscht, unabhängig davon, ob die Erkennung erfolgreich war oder nicht.
Das Python-Skript: Der Ort ist /usr/share/asterisk/agi-bin/whisper_vermittlung.py (Download als Zip-File: whisper_vermittlung.py
#!/usr/bin/env python3
# /usr/share/asterisk/agi-bin/whisper_vermittlung.py
# Museumsprojekt Handvermittlung
# Erkennt Ziffernfolgen und Namen, gibt Nummer zurück
import sys
import os
import json
import subprocess
import whisper
from gtts import gTTS
MODELL_PFAD = "/opt/whisper-models/base.pt"
NAMEN_PFAD = "/etc/asterisk/vermittlung.json"
# ── AGI-Hilfsfunktionen ──────────────────────────────────────────────────────
def agi_send(cmd):
sys.stdout.write(cmd + "\n")
sys.stdout.flush()
def agi_read():
return sys.stdin.readline().strip()
def agi_log(msg):
agi_send(f'VERBOSE "{msg}" 1')
agi_read()
def agi_set_var(name, value):
agi_send(f"SET VARIABLE {name} {value}")
agi_read()
def agi_header_lesen():
while True:
line = sys.stdin.readline().strip()
if not line:
break
# ── Namensliste laden ────────────────────────────────────────────────────────
def namen_laden():
try:
with open(NAMEN_PFAD, 'r', encoding='utf-8') as f:
daten = json.load(f)
return daten.get("nebenstellen", {})
except Exception as e:
return {}
# ── Fuzzy-Matching ───────────────────────────────────────────────────────────
def levenshtein(a, b):
if len(a) < len(b):
return levenshtein(b, a)
if len(b) == 0:
return len(a)
prev = list(range(len(b) + 1))
for i, ca in enumerate(a):
curr = [i + 1]
for j, cb in enumerate(b):
curr.append(min(
prev[j + 1] + 1,
curr[j] + 1,
prev[j] + (ca != cb)
))
prev = curr
return prev[-1]
def namen_suchen(text, nebenstellen, schwelle=2):
woerter = text.lower().split()
woerter = [w.strip(".,!?-") for w in woerter]
# Einzel- und Zwei-Wort-Kombinationen bilden
kandidaten = []
for i, w in enumerate(woerter):
kandidaten.append(w) # einzelnes Wort
if i + 1 < len(woerter):
kandidaten.append(w + " " + woerter[i+1]) # Zwei-Wort-Kombination
for kandidat in kandidaten:
# Exakter Treffer
if kandidat in nebenstellen:
return kandidat, nebenstellen[kandidat]
# Fuzzy-Treffer
bester = None
beste_dist = schwelle + 1
for name in nebenstellen:
dist = levenshtein(kandidat, name)
if dist < beste_dist:
beste_dist = dist
bester = name
if bester and beste_dist <= schwelle:
return bester, nebenstellen[bester]
return None, None
# ── Ziffern extrahieren ──────────────────────────────────────────────────────
def ziffern_extrahieren(text):
ZIFFER_MAP = {
"null": "0", "0": "0",
"eins": "1", "1": "1", "ein": "1", "eine": "1",
"zwei": "2", "2": "2", "zwo": "2",
"drei": "3", "3": "3",
"vier": "4", "4": "4",
"fünf": "5", "5": "5",
"sechs": "6", "6": "6",
"sieben": "7", "7": "7",
"acht": "8", "8": "8",
"neun": "9", "9": "9",
}
erkannte = []
for char in ".,-?!":
text = text.replace(char, " ")
for wort in text.split():
w = wort.strip()
if w in ZIFFER_MAP:
erkannte.append(ZIFFER_MAP[w])
else:
if w.isdigit():
erkannte.extend(list(w))
return "".join(erkannte)
# ── gTTS Ansage ──────────────────────────────────────────────────────────────
def ansage_sprechen(text):
"""Erzeugt eine kurze Sprachansage via gTTS und spielt sie über Asterisk ab."""
mp3_pfad = "/tmp/ansage.mp3"
wav_pfad = "/tmp/ansage.wav"
try:
# gTTS erzeugt MP3
tts = gTTS(text=text, lang="de")
tts.save(mp3_pfad)
# sox konvertiert MP3 zu WAV für Asterisk
subprocess.run([
"sox", mp3_pfad,
"-r", "8000",
"-c", "1",
"-e", "signed-integer",
"-b", "16",
wav_pfad
], check=True)
# Asterisk abspielen
agi_send("STREAM FILE /tmp/ansage \"\"")
agi_read()
except Exception as e:
agi_log(f"gTTS Fehler: {e}")
finally:
try:
os.remove(mp3_pfad)
os.remove(wav_pfad)
except:
pass
# ── Hauptprogramm ────────────────────────────────────────────────────────────
def main():
agi_header_lesen()
agi_log("whisper_vermittlung.py gestartet")
if len(sys.argv) < 2:
agi_log("Fehler: kein WAV-Pfad übergeben")
agi_set_var("RECOGNIZED", "error")
return
wav_pfad = sys.argv[1]
temp_wav = "/tmp/whisper_clean.wav"
if not os.path.exists(wav_pfad):
if os.path.exists(wav_pfad + ".wav"):
wav_pfad = wav_pfad + ".wav"
else:
agi_log(f"Datei nicht gefunden: {wav_pfad}")
agi_set_var("RECOGNIZED", "error")
return
# Namensliste laden
nebenstellen = namen_laden()
if not nebenstellen:
agi_log("Warnung: Namensliste leer oder nicht gefunden")
# Prompt aus Namen und Nummern bauen
nummern_prompt = " ".join(nebenstellen.values())
namen_prompt = " ".join(nebenstellen.keys())
try:
# 1. AUDIO-FILTERING: Optimiert für Telefon-Frequenzen
subprocess.run([
"sox", wav_pfad, "-r", "16000", "-c", "1", temp_wav,
"highpass", "300", "lowpass", "3900", "norm", "-6"
], check=True)
# 2. MODELL LADEN
model = whisper.load_model(MODELL_PFAD)
# 3. TRANSKRIPTION
result = model.transcribe(
temp_wav,
language="de",
fp16=False,
temperature=0,
beam_size=10,
best_of=10,
condition_on_previous_text=False,
initial_prompt="Nebenstellen: " + "1004 1088 1006 1033 1831 " + \
"1040 1073 1066 1822 1832 1834 1837 1839 1844 1847 222 " + \
"333 10883 1050 1049 1059 1023 " + "junghard volker ralf " + \
"roland silvia inge sebastian michael christian jürgen " + \
"benjamin wolfgang rainer uwe thomas axel musik zeitansage " + \
"deutschlandfunk wetter bitcoin kurs konfererenzraum " + \
"lange janson meine nummer heise online datum kontrafunk " + \
"datum deutsch datum englisch " + \
"postleitzahlen volker smartphone raspi mobil temperatur laufzeit echotest ",
compression_ratio_threshold=2.4,
logprob_threshold=-1.0,
no_speech_threshold=0.6
)
rohtext = result["text"].strip().lower()
agi_log(f"ROHTEXT: [{rohtext}]")
# 4. Zuerst Ziffernfolge suchen
ziffern = ziffern_extrahieren(rohtext)
if ziffern and len(ziffern) >= 3:
agi_log(f"Ziffern erkannt: {ziffern}")
agi_set_var("RECOGNIZED", ziffern)
agi_set_var("RECOGNIZED_TYPE", "nummer")
return
# 5. Dann Name suchen
name, nummer = namen_suchen(rohtext, nebenstellen)
if name:
agi_log(f"Name erkannt: {name} -> {nummer}")
# gTTS Bestätigung abspielen
ansage_sprechen(f"Verbindungsaufbau mit {name.capitalize()}.")
agi_set_var("RECOGNIZED", nummer)
agi_set_var("RECOGNIZED_NAME", name)
agi_set_var("RECOGNIZED_TYPE", "name")
return
# 6. Nichts gefunden
agi_log("Nichts erkannt")
agi_set_var("RECOGNIZED", "nichts")
agi_set_var("RECOGNIZED_TYPE", "nichts")
except Exception as e:
agi_log(f"Fehler: {e}")
agi_set_var("RECOGNIZED", "error")
finally:
try:
os.remove(temp_wav)
os.remove(wav_pfad)
except:
pass
if __name__ == "__main__":
main()
Das json-File: Die vermittlung.json gehört nach /etc/asterisk und kann jederzeit erweitert werden. Die Daten sind hier fiktiv.
{
"nebenstellen": {
"uwe": "2037",
"ralf": "3339",
"thomas": "1144",
"trump donald": "4450",
"zeitansage deutschland": "119",
"deutschlandfunk": "401",
"wetter deutschland": "353",
"bitcoin kurs": "356",
"konferenzraum": "8001",
"wetter postleitzahlen": "354",
"echotest": "223",
"raspi laufzeit": "350",
"raspi temperatur": "349",
"meine nummer": "55555",
"heise online": "355",
"kontrafunk": "420",
"datum englisch": "2424",
"datum deutsch": "88403002",
"musik": "349"
}
}
Auszug aus der extension.conf: Ort: etc/asterisk. Mit der 500 wird die Vermittlung aufgerufen. Das besondere hier ist, dass die vom Pythonskript aufgebauten Verbindungen per IAX2 zu einem anderen Asterisk-Server geleitet werden.
; IAX2-Verbindung zum Raspi11 mit der Vorwahl 8835
exten => _8835X.,1,NoOp(IAX2 - Esprimo ruft Raspi an mit Vorwahl 8835)
same => n,Dial(IAX2/outgoing-raspi111/${EXTEN:4})
exten => 500,1,Answer(2)
same => n,Set(CHANNEL(language)=de)
same => n,Playback(de/vermittlung/vermittlung1)
same => n,Set(AGC(RX)=on)
same => n,Set(VOLUME(RX)=2.5)
same => n,Record(/tmp/sprache.wav,3,20,s)
same => n,Playback(beep)
same => n,AGI(whisper_vermittlung.py,/tmp/sprache.wav)
same => n,GotoIf($["${RECOGNIZED}" = "nichts"]?no_number,1)
same => n,GotoIf($["${RECOGNIZED}" = "error"]?no_number,1)
same => n,NoOp(Typ: ${RECOGNIZED_TYPE} Name: ${RECOGNIZED_NAME} Nummer: ${RECOGNIZED})
same => n,Playback(de/vermittlung/vermittlung3)
same => n,Wait(1)
same => n,SayDigits(${RECOGNIZED})
same => n,Wait(1)
same => n,Playback(de/vermittlung/ich_wiederhole)
same => n,Wait(1)
same => n,SayDigits(${RECOGNIZED})
same => n,Wait(1)
same => n,Dial(IAX2/outgoing-raspi111/${RECOGNIZED})
same => n,Hangup()
; exten => no_number,1,Playback(beep)
; same => n,Hangup()
Sprachdateteien: Sie sind bei mir im Ordner /usr/share/asterisk/sounds/de/vermittlung untergebracht.
Obiges Video: Was in Echtzeit in der Asterisk-Konsole beim Aufruf der Vermittlung passiert.
Wie sich dieses Projekt über zwei Tage entwickelt hatte: Es begann mit einer simplen Idee: Eine historische Telefonvermittlung soll Anrufe per Spracherkennung weiterleiten. Klingt machbar, dachte ich. Zwei Tage später weiß ich, dass der Teufel im Detail steckt.
Der erste Kandidat war Vosk, eine lokale Open-Source-Spracherkennung. Die Idee war elegant: Audio direkt aus Asterisk per EAGI-Schnittstelle streamen, kein Zwischenspeichern, keine Verzögerung. Die Realität war ernüchternd. Vosk verweigerte konsequent die Arbeit mit der kryptischen Meldung „Failed to process waveform“. Stundenlange Fehlersuche, Hex-Dumps des Audiostreams, verschiedene Konvertierungsversuche – nichts half. EAGI und Vosk wollten einfach nicht miteinander.
Also Plan B: WAV-Datei aufnehmen, sox zur Aufbereitung, dann Vosk. Das funktionierte – fast. Das kleine deutsche Modell kannte das Wort „fünf“ schlicht nicht, zumindest nicht mit aktivierter Grammar. Ohne Grammar wurde es erkannt, mit Grammar nicht. Ein Bug, eine Eigenart, wer weiß. Dazu kam dass Vosk bei jedem Anruf das Modell neu laden musste – mehrere Sekunden Wartezeit, für eine Vermittlung inakzeptabel. Vosk flog raus.
Whisper von OpenAI war die Rettung. Ebenfalls lokal, ebenfalls kostenlos, aber deutlich intelligenter. Allerdings auch hier kein einfacher Weg. Das tiny-Modell halluzinierte fröhlich „1, 2, 3, 4“ wenn man eine vierstellige Nummer sprach. Das base-Modell war besser, aber der entscheidende Durchbruch kam erst mit dem initial_prompt – einer Liste aller bekannten Nummern und Namen die Whisper als Kontext bekommt. Ohne diesen Prompt rät Whisper wild drauflos.
Dann das Feintuning mit verschiedenen Telefonen. Jedes Gerät klingt anders, jedes hat andere Codec-Einstellungen, manche sind leiser, manche haben mehr Rauschen. AGC einschalten, Lautstärke verstärken, sox-Filter anpassen. Parameter wie beam_size, best_of und no_speech_threshold wurden iterativ optimiert bis die Erkennungsrate über 95% lag.
Damit es sich auch wie eine echte Vermittlung anfühlt, mussten noch deutsche Sprachprompts her. Asterisk bringt von Haus aus englische Ansagen mit, die deutschen Pendants mussten erst beschafft werden. Zusätzlich wurden drei eigene Ansagen benötigt – eine Begrüßung, eine Wartemeldung und eine Verbindungsansage. Die wurden per Text-to-Speech online generiert, im richtigen Format für Asterisk aufbereitet und eingebunden. Wenn schon, dann richtig.
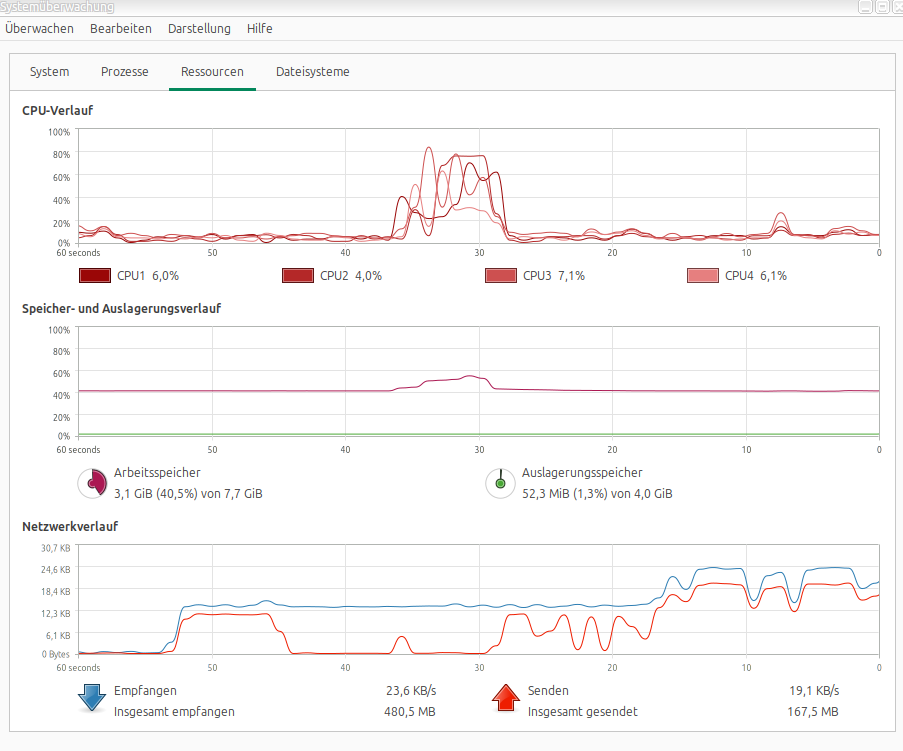
Ursprünglich sollte das alles auf einem Raspberry Pi laufen. Der Pi ist bereits als IAX2-Gateway im Einsatz, wäre also naheliegend gewesen. Aber Whisper base auf einem Pi ist schlicht zu langsam – die Wartezeit wäre für Museumsbesucher unzumutbar. Also wurde die Spracherkennung auf einen Fujitsu Esprimo Q520 ausgelagert, einen kleinen aber feinen Mini-PC mit 8 GB RAM. Auch der geht während der Erkennung kurz in die Knie – alle vier CPU-Kerne springen auf 60 bis 90 Prozent. Eine Nvidia-Grafikkarte würde die Verarbeitungszeit von fünf Sekunden auf unter eine Sekunde drücken.
Als letztes kam noch eine kleine aber feine Erweiterung hinzu: Wenn ein Name erkannt wird, bestätigt das System die Erkennung mit einer gesprochenen Ansage – „Verbindungsaufbau mit Michael“ zum Beispiel. Umgesetzt mit gTTS, dem Google Text-to-Speech Modul für Python. Wenige Zeilen Code, gTTS erzeugt eine MP3, sox konvertiert sie ins richtige Format für Asterisk, Asterisk spielt sie ab, die Datei wird gelöscht. Das war dank Claude in weniger als einer Stunde erledigt – inklusive dem kleinen Stolperstein dass sox das Paket libsox-fmt-mp3 braucht um MP3-Dateien lesen zu können, und dass Asterisk kein a-law WAV mag sondern PCM 16-bit. Auch das gehört dazu: Selbst kleine Erweiterungen haben ihre Tücken.
Den praktischen Nutzen im Alltag darf man dabei nicht vergessen: Wer kennt schon alle Durchwahlen auswendig? Namen sprechen und verbunden werden ist deutlich komfortabler als im Telefonbuch blättern. Für den produktiven Einsatz braucht man allerdings schnellere Hardware – die fünf Sekunden Wartezeit erinnern im Moment eher an die Geduld die man früher bei einer echten Handvermittlung aufbringen musste. Was für das Museumsprojekt durchaus seinen Charme hat, im Büroalltag aber schnell zur Geduldsprobe wird.
Warum so ein Projekt für Telefonie mit kostenlosen Spracherkennungsprogrammen so schwierig ist: G.711 (alaw/ulaw), der klassische Telefonstandard, ist technisch keine Kompression im eigentlichen Sinne, sondern logarithmische PCM-Quantisierung mit 8 kHz Samplingrate – was nach Nyquist maximal 4 kHz Frequenzübertragung bedeutet. Das reicht für Sprache gerade so aus, ist aber weit entfernt von dem, was Spracherkennungsmodelle erwarten. G.722 dreht das teilweise um: Es ist zwar komprimiert (ADPCM), überträgt aber Frequenzen bis 8 kHz und klingt als HD-Voice deutlich natürlicher. Mobilfunk ist nochmal eine andere Baustelle – Codecs wie AMR oder AMR-WB sind stark verlustbehaftet und auf minimale Funkbandbreite optimiert. Bei schlechtem Empfang reduziert der Codec die Bitrate dynamisch, was Artefakte und den typischen metallischen Klang erzeugt. Dazu kommen Paketlöcher bei LTE und ständige Handover zwischen Funkmasten.
Für Spracherkennung ist das alles problematisch, weil die Modelle nicht nur mit begrenzter Bandbreite klarkommen müssen, sondern auch mit codec-spezifischen Artefakten, die im Trainingsdatensatz schlicht nicht vorhanden sind. Android Voice Typing würde damit sehr fehlerhafte Ergebnisse liefern, Whisper hat zusätzlich das Architekturproblem – für Batch-Verarbeitung gebaut, nicht für Echtzeit-Streams, halluziniert bei Stille und erwartet 16 kHz. Vosk war der Versuch einer schlanken Streaming-Lösung, ist aber in der Praxis zu ungenau – schlechte Ziffernerkennung und generell unbefriedigende Ergebnisse.
Die großen Callcenter haben das Problem gelöst, aber mit erheblichem Aufwand: spezialisierte kommerzielle Systeme von Nuance, Google CCAI oder Amazon Transcribe, die explizit auf echten Telefongesprächen trainiert wurden und jahrelange Optimierung auf die verschiedenen Codec-Artefakte, 4 kHz Bandbreite und Echtzeit-Streaming hinter sich haben.
Prinzipiell könnte man als Privatperson ebenfalls auf solche Cloud-APIs zugreifen – Google Speech-to-Text, Amazon Transcribe oder Azure Speech bieten das an, und die Qualität wäre tatsächlich gut. Das Problem ist der Preis: Bei einem Asterisk-Hobbyprojekt summieren sich die Kosten pro Minute schnell auf einen Betrag, der nicht mehr verhältnismäßig ist. Was für ein Callcenter mit klarem Geschäftsmodell selbstverständlich ist, wird für den privaten Bastler schnell zum Kostenproblem.
Für selbst gehostete Lösungen mit Asterisk bleibt die Lücke damit bestehen: Gute Offline-Spracherkennung für Telefonie-Audio gibt es im Open-Source-Bereich schlicht nicht zufriedenstellend, und die guten Lösungen sind entweder zu teuer oder nur in der Cloud verfügbar.
Diskussion:
https://www.wumpus-gollum-forum.de/forum/thread.php?board=73&thread=111
https://www.reddit.com/r/Asterisk/comments/1rn7f7y/a_voicecontrolled_telephone_switchboard_with/
Die zweite verbesserte Version (empfehlenswert):
Das Museumsprojekt „Fräulein vom Amt“ hat eine wichtige Weiterentwicklung erfahren. Für die Sprachausgabe wird jetzt ausschließlich Google Text-to-Speech (gTTS) eingesetzt, und das macht einen erheblichen Unterschied.
Früher wurden vorproduzierte Audiodateien abgespielt. Das klang oft holprig und zusammengestückelt, weil jede Ansage aus einzelnen Bausteinen zusammengesetzt wurde. Mit gTTS wird der gesamte Satz in einem Stück synthetisiert und klingt dadurch deutlich flüssiger und natürlicher — fast wie ein echtes Gespräch. Wer die Vermittlung anruft, hat das Gefühl, tatsächlich mit einer Telefonistin zu sprechen.
Ein weiterer großer Vorteil ist, dass man überhaupt keine Audiodateien mehr erstellen, pflegen oder auf dem Server ablegen muss. Der Text wird direkt zur Laufzeit in Sprache umgewandelt. Das spart Zeit und vermeidet Fehlerquellen. Soll eine Ansage geändert werden, ändert man einfach den Text im Programm — fertig.
Besonders elegant ist die Mehrsprachigkeit. Um das System auf Englisch oder Französisch umzustellen, genügt es, eine einzige Variable im Skript zu ändern. gTTS übernimmt dann automatisch die korrekte Aussprache in der gewünschten Sprache, ohne dass neue Aufnahmen nötig wären.
Auch der Gesprächsablauf selbst wurde verbessert. Das Programm führt jetzt einen echten Dialog. Wenn die Spracherkennung einen Namen oder eine Nummer erkannt hat, fragt das System zur Bestätigung nach, zum Beispiel: „Soll ich Sie mit Michael, Nebenstelle 1066, verbinden?“ Wird die Antwort nicht verstanden, fragt das Programm gezielt nach, statt einfach aufzulegen. Erst nach mehreren erfolglosen Versuchen beendet es das Gespräch höflich.
Ein Detail das zunächst unscheinbar wirkt, aber im Alltag wichtig ist: lange Telefonnummern werden jetzt Ziffer für Ziffer aufgesagt. Nummern bis zu vier Stellen spricht gTTS als Zahl aus, was gut verständlich ist. Bei längeren Nummern wie externen Anschlüssen werden die einzelnen Ziffern nacheinander genannt, damit der Anrufer die Nummer sicher aufnehmen kann.
Das Telefonbuch mit allen Namen und Nebenstellen liegt in einer einfachen JSON-Datei. Wer einen neuen Teilnehmer einträgt oder eine Nummer ändert, muss nichts weiter tun — kein Neustart des Servers, keine Neukompilierung, keine neue Audiodatei. Bei jedem Anruf lädt das Programm die JSON-Datei automatisch und baut daraus auch gleich den Kontext für die Spracherkennung auf. Namen und Nummern aus dem Telefonbuch werden von Whisper dadurch bevorzugt erkannt.
Das Ergebnis ist ein System das sich tatsächlich wie eine echte Vermittlung anfühlt — reaktionsschnell, verständlich und pflegeleicht.
Das neue Pythonskript: /usr/share/asterisk/agi-bin/whisper_vermittlung.py
#!/usr/bin/env python3
# /usr/share/asterisk/agi-bin/whisper_vermittlung.py
# Museumsprojekt "Fräulein vom Amt" - Handvermittlung
# Vollständiger Dialog mit Bestätigung, Wiederholung und gTTS
import sys
import os
import re
import json
import subprocess
import whisper
from gtts import gTTS
MODELL_PFAD = "/opt/whisper-models/base.pt"
NAMEN_PFAD = "/etc/asterisk/vermittlung.json"
MAX_VERSUCHE = 3
SPRACHE = "de"
KANAL_FORMAT = "alaw" # Standardwert, wird aus AGI-Header überschrieben
# ── AGI-Hilfsfunktionen ──────────────────────────────────────────────────────
def agi_send(cmd):
sys.stdout.write(cmd + "\n")
sys.stdout.flush()
def agi_read():
return sys.stdin.readline().strip()
def agi_log(msg):
agi_send(f'VERBOSE "{msg}" 1')
agi_read()
def agi_set_var(name, value):
agi_send(f"SET VARIABLE {name} {value}")
agi_read()
def agi_get_var(name):
agi_send(f"GET VARIABLE {name}")
result = agi_read()
match = re.search(r'\((.+?)\)', result)
return match.group(1) if match else ""
def agi_header_lesen():
"""Liest AGI-Header und erkennt Kanalformat (g722 oder alaw/ulaw)."""
global KANAL_FORMAT
while True:
line = sys.stdin.readline().strip()
if not line:
break
# agi_channel_format: g722 oder ulaw oder alaw
if line.startswith("agi_channel_format:"):
wert = line.split(":", 1)[1].strip().lower()
if "g722" in wert:
KANAL_FORMAT = "g722"
else:
KANAL_FORMAT = "alaw"
def agi_record(ziel_wav, max_sekunden=8, stille_sekunden=2):
"""Nimmt Audio auf über Asterisk RECORD FILE."""
agi_send(f'RECORD FILE {ziel_wav} wav "beep" {max_sekunden * 1000} s={stille_sekunden}')
agi_read()
# ── Namensliste laden ────────────────────────────────────────────────────────
def namen_laden():
try:
with open(NAMEN_PFAD, 'r', encoding='utf-8') as f:
daten = json.load(f)
return daten.get("nebenstellen", {})
except Exception as e:
agi_log(f"JSON Ladefehler: {e}")
return {}
def initial_prompt_bauen(nebenstellen):
"""Baut initial_prompt automatisch aus JSON - keine manuelle Pflege nötig!"""
namen = " ".join(nebenstellen.keys())
nummern = " ".join(nebenstellen.values())
return f"Nebenstellen: {nummern} {namen}"
# ── Nummer aufbereiten für gTTS ──────────────────────────────────────────────
def nummer_fuer_tts(nummer):
"""
Bis 4 Stellen: als Zahl sprechen (gTTS macht das gut).
Ab 5 Stellen: Ziffer für Ziffer mit Leerzeichen trennen,
damit gTTS jede Ziffer einzeln ausspricht.
Beispiel: "1066" -> "1066"
"88406051" -> "8 8 4 0 6 0 5 1"
"""
n = str(nummer).strip()
if len(n) <= 4:
return n
else:
return " ".join(list(n))
# ── gTTS Ansage ──────────────────────────────────────────────────────────────
def ansage(text):
"""Erzeugt Sprachansage via gTTS und spielt sie über Asterisk ab.
Samplerate wird dynamisch je nach Kanalformat gewählt:
g722 -> 16000 Hz, alaw/ulaw -> 8000 Hz.
Dateinamen sind pro Prozess eindeutig (pid) um Konflikte
bei gleichzeitigen Anrufen zu vermeiden.
"""
pid = os.getpid()
mp3_pfad = f"/tmp/ansage_{pid}.mp3"
wav_pfad = f"/tmp/ansage_{pid}" # Asterisk ergänzt .wav selbst
wav_voll = f"/tmp/ansage_{pid}.wav"
samplerate = "16000" if KANAL_FORMAT == "g722" else "8000"
try:
tts = gTTS(text=text, lang=SPRACHE)
tts.save(mp3_pfad)
subprocess.run([
"sox", mp3_pfad,
"-r", samplerate, "-c", "1",
"-e", "signed-integer", "-b", "16",
wav_voll
], check=True, stderr=subprocess.DEVNULL)
agi_send(f'STREAM FILE {wav_pfad} ""')
agi_read()
except Exception as e:
agi_log(f"gTTS Fehler: {e}")
finally:
for f in [mp3_pfad, wav_voll]:
try:
os.remove(f)
except:
pass
# ── Fuzzy-Matching ───────────────────────────────────────────────────────────
def levenshtein(a, b):
if len(a) < len(b):
return levenshtein(b, a)
if len(b) == 0:
return len(a)
prev = list(range(len(b) + 1))
for i, ca in enumerate(a):
curr = [i + 1]
for j, cb in enumerate(b):
curr.append(min(
prev[j + 1] + 1,
curr[j] + 1,
prev[j] + (ca != cb)
))
prev = curr
return prev[-1]
def namen_suchen(text, nebenstellen, schwelle=2):
woerter = text.lower().split()
woerter = [w.strip(".,!?-") for w in woerter]
kandidaten = []
for i, w in enumerate(woerter):
kandidaten.append(w)
if i + 1 < len(woerter):
kandidaten.append(w + " " + woerter[i + 1])
if i + 2 < len(woerter):
kandidaten.append(w + " " + woerter[i + 1] + " " + woerter[i + 2])
for kandidat in kandidaten:
if kandidat in nebenstellen:
return kandidat, nebenstellen[kandidat]
bester = None
beste_dist = schwelle + 1
for name in nebenstellen:
dist = levenshtein(kandidat, name)
if dist < beste_dist:
beste_dist = dist
bester = name
if bester and beste_dist <= schwelle:
return bester, nebenstellen[bester]
return None, None
# ── Ziffern extrahieren ──────────────────────────────────────────────────────
def ziffern_extrahieren(text):
ZIFFER_MAP = {
"null": "0", "eins": "1", "ein": "1", "eine": "1",
"zwei": "2", "zwo": "2", "drei": "3", "vier": "4",
"fünf": "5", "sechs": "6", "sieben": "7",
"acht": "8", "neun": "9",
}
for char in ".,-?!":
text = text.replace(char, " ")
erkannte = []
for wort in text.split():
w = wort.strip()
if w in ZIFFER_MAP:
erkannte.append(ZIFFER_MAP[w])
elif w.isdigit():
erkannte.extend(list(w))
return "".join(erkannte)
# ── Audio aufnehmen und transkribieren ───────────────────────────────────────
def audio_filtern(roh_wav_voll, temp_wav):
"""Filtert Audio für Whisper."""
try:
subprocess.run([
"sox", roh_wav_voll,
"-r", "16000", "-c", "1", temp_wav,
"highpass", "300", "lowpass", "3200", "norm", "-6"
], check=True, stderr=subprocess.DEVNULL)
except Exception as e:
raise RuntimeError(f"sox Fehler: {e}")
def aufnehmen_und_erkennen(model, initial_prompt, aufnahme_nr=0):
"""Nimmt Audio auf (Name/Nummer), filtert und transkribiert."""
pid = os.getpid()
roh_wav = f"/tmp/vermittlung_roh_{pid}_{aufnahme_nr}"
temp_wav = f"/tmp/vermittlung_clean_{pid}_{aufnahme_nr}.wav"
roh_wav_voll = roh_wav + ".wav"
agi_record(roh_wav, max_sekunden=8, stille_sekunden=2)
if not os.path.exists(roh_wav_voll):
agi_log(f"Aufnahme nicht gefunden: {roh_wav_voll}")
return ""
try:
audio_filtern(roh_wav_voll, temp_wav)
result = model.transcribe(
temp_wav,
language=SPRACHE,
fp16=False,
temperature=0,
beam_size=4,
best_of=2,
condition_on_previous_text=False,
initial_prompt=initial_prompt,
compression_ratio_threshold=2.2,
logprob_threshold=-0.8,
no_speech_threshold=0.87
)
rohtext = result["text"].strip().lower()
agi_log(f"ROHTEXT [{aufnahme_nr}]: [{rohtext}]")
return rohtext
except Exception as e:
agi_log(f"Erkennungsfehler: {e}")
return ""
finally:
for f in [roh_wav_voll, temp_wav]:
try:
os.remove(f)
except:
pass
def aufnehmen_ja_nein(model, aufnahme_nr=0):
"""
Separate Aufnahme nur für Ja/Nein-Bestätigung.
Kürzere Aufnahme, niedrigere no_speech_threshold,
initial_prompt gezielt auf Ja/Nein.
"""
pid = os.getpid()
roh_wav = f"/tmp/vermittlung_roh_{pid}_{aufnahme_nr}"
temp_wav = f"/tmp/vermittlung_clean_{pid}_{aufnahme_nr}.wav"
roh_wav_voll = roh_wav + ".wav"
agi_record(roh_wav, max_sekunden=4, stille_sekunden=1)
if not os.path.exists(roh_wav_voll):
agi_log(f"Ja/Nein Aufnahme nicht gefunden: {roh_wav_voll}")
return ""
try:
audio_filtern(roh_wav_voll, temp_wav)
result = model.transcribe(
temp_wav,
language=SPRACHE,
fp16=False,
temperature=0,
beam_size=1,
best_of=1,
condition_on_previous_text=False,
initial_prompt="Ja. Nein. Ja bitte. Nein danke.",
compression_ratio_threshold=2.2,
logprob_threshold=-0.5,
no_speech_threshold=0.6
)
rohtext = result["text"].strip().lower()
agi_log(f"ROHTEXT [{aufnahme_nr}]: [{rohtext}]")
return rohtext
except Exception as e:
agi_log(f"Ja/Nein Erkennungsfehler: {e}")
return ""
finally:
for f in [roh_wav_voll, temp_wav]:
try:
os.remove(f)
except:
pass
# ── Ja/Nein erkennen ─────────────────────────────────────────────────────────
def ja_nein_erkennen(text):
"""Gibt 'ja', 'nein' oder 'unbekannt' zurück."""
ja_woerter = ["ja", "jawohl", "bitte", "ja bitte", "stimmt", "richtig",
"genau", "korrekt", "yes", "ok", "okay"]
nein_woerter = ["nein", "ne", "nicht", "falsch", "stop", "abbruch",
"anderer", "andere", "no"]
t = text.lower().strip()
for w in ja_woerter:
if w in t:
return "ja"
for w in nein_woerter:
if w in t:
return "nein"
return "unbekannt"
def bestaetigung_einholen(model, initial_prompt, aufnahme_basis):
"""
Eigene Schleife für Ja/Nein-Bestätigung.
Gibt 'ja', 'nein' oder 'abbruch' zurück.
Wiederholt bis zu 2x bei nicht verstanden.
"""
for i in range(2):
antwort_text = aufnehmen_ja_nein(model, aufnahme_basis + i)
bestaetigung = ja_nein_erkennen(antwort_text)
agi_log(f"Bestätigung [{i}]: [{antwort_text}] -> {bestaetigung}")
if bestaetigung == "ja":
return "ja"
elif bestaetigung == "nein":
return "nein"
else:
if i < 1:
ansage("Bitte antworten Sie mit Ja oder Nein.")
else:
return "abbruch"
return "abbruch"
# ── Hauptdialog ──────────────────────────────────────────────────────────────
def main():
agi_header_lesen()
agi_log("Fräulein vom Amt gestartet")
agi_log(f"Kanalformat: {KANAL_FORMAT}")
# Namensliste laden
nebenstellen = namen_laden()
if not nebenstellen:
agi_log("FEHLER: Namensliste leer")
agi_set_var("RECOGNIZED", "error")
return
# initial_prompt automatisch aus JSON bauen
initial_prompt = initial_prompt_bauen(nebenstellen)
agi_log(f"Prompt gebaut: {len(nebenstellen)} Einträge")
# Modell laden
try:
model = whisper.load_model(MODELL_PFAD)
except Exception as e:
agi_log(f"Modell Ladefehler: {e}")
agi_set_var("RECOGNIZED", "error")
return
# ── DIALOG-SCHLEIFE ──────────────────────────────────────────────────────
ansage("Vermittlung, bitte?")
for versuch in range(MAX_VERSUCHE):
# Audio aufnehmen
rohtext = aufnehmen_und_erkennen(model, initial_prompt, versuch)
if not rohtext:
ansage("Ich habe Sie nicht verstanden. Bitte wiederholen Sie.")
continue
# Abbruch erkennen
abbruch_woerter = ["auf wiederhören", "tschüss", "danke", "schluss",
"beenden", "wiederhören", "tschau"]
if any(w in rohtext for w in abbruch_woerter):
ansage("Auf Wiederhören!")
agi_set_var("RECOGNIZED", "auflegen")
return
# Ziffernfolge suchen
ziffern = ziffern_extrahieren(rohtext)
if ziffern and len(ziffern) >= 3:
agi_log(f"Ziffern erkannt: {ziffern}")
ansage(f"Soll ich Sie mit Nebenstelle {nummer_fuer_tts(ziffern)} verbinden?")
bestaetigung = bestaetigung_einholen(model, initial_prompt, versuch * 100 + 10)
if bestaetigung == "ja":
ansage("Einen Moment bitte.")
agi_set_var("RECOGNIZED", ziffern)
agi_set_var("RECOGNIZED_TYPE", "nummer")
agi_set_var("RECOGNIZED_NAME", ziffern)
return
elif bestaetigung == "nein":
ansage("Wen darf ich verbinden?")
continue
else:
ansage("Ich habe Sie nicht verstanden. Auf Wiederhören!")
agi_set_var("RECOGNIZED", "auflegen")
return
# Name suchen
name, nummer = namen_suchen(rohtext, nebenstellen)
if name and nummer:
agi_log(f"Name erkannt: {name} -> {nummer}")
ansage(f"Soll ich Sie mit {name.title()}, Nebenstelle {nummer_fuer_tts(nummer)}, verbinden?")
bestaetigung = bestaetigung_einholen(model, initial_prompt, versuch * 100 + 20)
if bestaetigung == "ja":
ansage("Einen Moment bitte.")
agi_set_var("RECOGNIZED", nummer)
agi_set_var("RECOGNIZED_TYPE", "name")
agi_set_var("RECOGNIZED_NAME", name)
return
elif bestaetigung == "nein":
ansage("Wen darf ich verbinden?")
continue
else:
ansage("Ich habe Sie nicht verstanden. Auf Wiederhören!")
agi_set_var("RECOGNIZED", "auflegen")
return
# Nichts erkannt
agi_log("Nichts erkannt")
if versuch < MAX_VERSUCHE - 1:
ansage("Ich habe Sie nicht verstanden. Wen darf ich verbinden?")
else:
ansage("Leider konnte ich nicht helfen. Auf Wiederhören!")
agi_set_var("RECOGNIZED", "auflegen")
# Nach MAX_VERSUCHE
agi_set_var("RECOGNIZED", "auflegen")
if __name__ == "__main__":
main()
Die extension 500 im Kontext [telefone] für den Aufruf der Vermittlung: in der extensions.conf: /etc/asterisk – 500 wählen
[telefone]
; ── Fräulein vom Amt ────────────────────────────────────────────────────────
; Nebenstelle 500 - Sprachvermittlung
; Dialog läuft komplett in whisper_vermittlung.py
; RECOGNIZED wird gesetzt auf: Nummer | "auflegen" | "error"
exten => 500,1,Noop(Sprachgesteuerte Vermittlung. Teilnehmer: "${CALLERID(name)}" <${CALLERID(num)}>)
same => n,Answer(2)
same => n,Set(CHANNEL(language)=de)
; same => n,Set(AGC(RX)=off)
; same => n,Set(VOLUME(RX)=1)
; same => n,Set(VOLUME(TX)=1)
; Kompletter Dialog läuft im AGI
; whisper_vermittlung.py übernimmt:
; - Ansagen via gTTS
; - Aufnahme und Erkennung
; - Bestätigungsdialog
; - Setzt RECOGNIZED, RECOGNIZED_TYPE, RECOGNIZED_NAME
same => n,AGI(whisper_vermittlung.py)
; Auswertung
same => n,GotoIf($["${RECOGNIZED}" = "auflegen"]?hangup,1)
same => n,GotoIf($["${RECOGNIZED}" = "error"]?hangup,1)
same => n,GotoIf($["${RECOGNIZED}" = "nichts"]?hangup,1)
; Verbinden
same => n,NoOp(Verbinde: Typ=${RECOGNIZED_TYPE} Name=${RECOGNIZED_NAME} Nummer=${RECOGNIZED})
same => n,Dial(IAX2/outgoing-raspi111/${RECOGNIZED})
same => n,Hangup()
; ── Auflegen ─────────────────────────────────────────────────────────────────
exten => hangup,1,Hangup()
Das json-file als „Telefonbuch“: Es befindet sich nach wie vor unter /etc/asterisk/vermittlung.json und es hat sich nicht geändert. Hier ein Beispiel mit fiktiven Nummern:
{
"nebenstellen": {
"jonas": "1009",
"hubert klein": "1095",
"hans müller": "1864",
"daniel düsentrieb": "1864",
"zeitansage deutschland": "119",
"zeitansage": "119",
"deutschlandfunk": "401",
"wetter deutschland": "353",
"wetterbericht": "353",
"bitcoin kurs": "356",
"konferenzraum": "8001",
"wetter postleitzahlen": "354",
"echotest deutsch": "223",
"echotest englisch": "222",
"echotest international": "4444",
"raspi laufzeit": "350",
"raspi temperatur": "349",
"meine nummer": "55555",
"heise online": "355",
"kontrafunk": "420",
"datum englisch": "2424",
"datum deutsch": "88403002",
"eigene stimme": "1000",
"musik": "333"
}
}
Die Spracherkennung erkennt jetzt auch Umgangssprache und reagiert auf die Stichwörter in der vermittlung.json
Verbesserungen: Der komplette Dialog — von der Begrüßung bis zum Klingeln beim Teilnehmer — verläuft jetzt kürzer, und die Zeitabläufe wirken natürlich und nicht mechanisch.
Die Spracherkennung verarbeitet umgangssprachliche Eingaben zuverlässig — Anrufer müssen nicht in kurzen Kommandos sprechen. Das System erkennt die relevanten Schlüsselwörter (Namen und Nebenstellen) aus einer JSON-Datei, auch wenn sie von anderem Text umgeben sind. Es funktioniert mit einem alten Wählscheibentelefon über eine Fritz!Box, also reines alaw-Schmalband. Die obere Grenzfrequenz des Bandpassfilters wurde von 3200 Hz auf 3900 Hz angehoben, was näher an der tatsächlichen Bandgrenze des klassischen Telefonnetzes liegt und die Konsonantenerkennung verbessert.
beam_size wurde von 10 auf 4 reduziert, best_of von 10 auf 2. Diese beiden Änderungen reduzieren die Rechenzeit auf dem Host-Rechner (Intel Core i3 Mini-PC) erheblich, ohne spürbare Einbußen bei der Erkennungsgenauigkeit. Bei einem geschlossenen Vokabular von rund 63 bekannten Namen ist aggressives Beam Search schlicht nicht nötig — der initial_prompt lenkt Whisper bereits stark in Richtung der erwarteten Namen.
Gleichzeitige Anrufer werden sauber getrennt: Asterisk startet pro Anruf einen eigenen AGI-Prozess, sodass jede temporäre Audiodatei durch Prozess-ID und einen Aufnahme-Index eindeutig benannt ist, zum Beispiel vermittlung_roh_23193_0.wav und vermittlung_roh_24817_0.wav. Datei-Konflikte sind auch bei gleichzeitiger Last nicht möglich.
Mehr zum Thema Asterisk-Telefonsoftware:
|
|
Asterisk-Telefonserver auf einem Raspberry Pi – Installation, Konfiguration, Programmierung, SIP, IAX2, AGI-Skripte, Sicherheit und Tipps zum praktischen Betrieb – 2.11.2022: Diese Seite richtet sich an jene, welche einen Asterisk-Telefon-Server auf einem Raspberry Pi betreiben möchten und später ein kleines Netzwerk aus Asterisk-Servern planen, um ein eigenständiges Telefonnetz aufzubauen. Los geht es mit der Installation von Raspbian und Asterisk auf einem Raspberry Pi und dann nach Lust und Laune immer tiefer in die Programmierung von Asterisk. Die Themen werden laufend erweitert.
Selbstverständlich muss es nicht unbedingt ein Raspberry Pi sein. Andere Linux-Rechner gehen auch. – weiter – |
