
3. März 2025 (aktualisiert am 8. März 2025)
Extrahiere mit nur einer URL das Transkript eines YouTube-Videos und erhalte eine präzise Zusammenfassung. Spare Stunden an Videozeit und fasse Inhalte in Minuten zusammen! Ein kleines Python-Skript macht es möglich. Und wenn du willst, kannst du in einem weiteren Schritt dir den Text vorlesen lassen.
Willst du den Inhalt eines einstündigen YouTube-Videos in nur wenigen Minuten erfassen? Mit dem YouTube Transkript Extractor wird das zur Realität. Dieses einfache Python-Skript revolutioniert die Art, wie du Videos konsumierst, indem es dir erlaubt, mit wenigen Klicks Transkripte zu extrahieren und in kompakte Zusammenfassungen zu verwandeln. Gib einfach die URL eines YouTube-Videos ein – der Rest erledigt sich fast von selbst. Getestet habe ich das Verfahren mit den kostenlosen KIs DeepSeek, ChatGPT und Grok3. Letzteres gefällt mir am besten. Hier ein Beispiel einer Zusammenfassung:
https://grok.com/share/bGVnYWN5_85847eac-2729-439f-9b27-70aca4c99118
Man muss den Text nicht ausdrucken. Er lässt sich bequem auf dem Smarpthone lesen. Außerdem lässt sich der Link zum Video anklicken.
Das Skript wurde auf meine Anregung von Grok3 erstellt. Das nachfolgende Foto ist ebenfalls von Grok3 für meinen Artikel erstellt worden. Zum Einsatz kam die kostenlose Version

Das Skript holt automatisch den Titel und das Transkript eines Videos und speichert beides in einer Textdatei. Diese Datei kannst du dann hochladen, etwa bei einem KI-Tool wie Grok, und erhältst eine detaillierte Zusammenfassung von etwa 1500 Wörtern – inklusive der Video-Überschrift und URL. Ein Video, das sonst 60 Minuten deiner Zeit beanspruchen würde, wird so auf 5–10 Minuten Lesezeit reduziert. Die Zeitersparnis ist der eigentliche Clou dieses kleinen, aber mächtigen Tools!
Vorsicht: Die KI macht bei ihren Zusammenfassungen manchmal Fehler. Sachverhalte werden verdreht oder die Rollen des Moderators und der Interviewpartner werden von der KI verwechselt.. Die durch KI generierten Zusammenfassungen sind als erste Orienierung sehr hilfreich. Der Lerneffekt ist ausgeprägt, wenn man die Zusammenfassung auf Fehler überprüft und von Hand korrigiert. Warum? Weil man sich durch die Videos nicht berieseln lässt. Eine aktive und kritische Auseinandersetzung mit den Aussagen wird auf diese Weise erzwungen. Übrigens kann man den meisten Youtube-Videos noch gut folgen, wenn sie mit 1,5-facher Geschwindigkeit laufen. So spart man sich Zeit und vermeidet Langeweile, was die Aufmerksamkeit erhöht.
Nach der Zusammenfassung kannst du das Ergebnis flexibel nutzen: Teile es per Link mit anderen oder erstelle mit einem Schreibprogramm wie LibreOffice ein PDF – alles mit nur ein paar Mausklicks. Das macht den YouTube Transkript Extractor ideal für Studierende, die Bildungsvideos zusammenfassen möchten, Berufstätige, die wichtige Infos aus Webinaren ziehen, oder Content-Ersteller, die Inhalte analysieren.
So funktioniert’s:
-
- Lade das Skript herunter und installiere die benötigten Bibliotheken (youtube-transcript-api, requests, beautifulsoup4) mit pip.
pip install youtube-transcript-api pip install requests pip install beautifulsoup4
- Lade das Skript herunter und installiere die benötigten Bibliotheken (youtube-transcript-api, requests, beautifulsoup4) mit pip.
-
- Gib die YouTube-URL ein – das Skript erstellt eine .txt-Datei mit Titel, URL und Transkript.
-
- Lade die Datei bei einer KI hoch und erhalte eine fertige Zusammenfassung.
-
- Teile oder speichere das Ergebnis nach Belieben.
Das Python-Skript: Kopiere es in eine unformatierte Text-Datei und vergebe ihr die Endung .py
from youtube_transcript_api import YouTubeTranscriptApi
import requests
from bs4 import BeautifulSoup
def get_video_title(url):
print(f"Versuche, Titel von {url} abzurufen...")
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text.replace(' - YouTube', '').strip()
print(f"Titel erfolgreich abgerufen: {title}")
return title
except Exception as e:
error_msg = f"Fehler beim Abrufen des Titels: {str(e)}"
print(error_msg)
return error_msg
def get_transcript(video_url):
print(f"Versuche, Transkript von {video_url} abzurufen...")
try:
if 'youtube.com/watch?v=' in video_url:
video_id = video_url.split('watch?v=')[1].split('&')[0]
elif 'youtu.be/' in video_url:
video_id = video_url.split('youtu.be/')[1].split('?')[0]
else:
error_msg = "Ungültige YouTube-URL"
print(error_msg)
return error_msg
print(f"Video-ID: {video_id}")
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['de', 'en'])
full_transcript = " ".join(entry['text'] for entry in transcript)
print(f"Transkript erfolgreich abgerufen: {full_transcript[:50]}...") # Erste 50 Zeichen anzeigen
return full_transcript
except Exception as e:
error_msg = f"Fehler beim Abrufen des Transkripts: {str(e)}"
print(error_msg)
return error_msg
def save_to_file(url, title, transcript):
print("Speichere in Datei...")
filename = "".join(c for c in title if c.isalnum() or c in " -_") + ".txt"
content = f"Titel: {title}\nURL: {url}\n\nTranskript:\n{transcript}\n\n"
content += "Bitte fasse das Transkript in einem Stück auf etwa 1500 Wörter zusammen und wähle als Überschrift die des Youtube-Videos und füge unter die Überschrift die URL des Youtube-Videos hinzu. Erzeuge die Zusammenfassung immer in deutscher Sprache."
with open(filename, 'w', encoding='utf-8') as file:
file.write(content)
print(f"Datei '{filename}' wurde erstellt.")
return filename
def main():
video_url = input("Bitte gib die YouTube-Video-URL ein: ")
title = get_video_title(video_url)
transcript = get_transcript(video_url)
# Nur abbrechen, wenn explizit ein Fehler zurückgegeben wurde
if title.startswith("Fehler") or transcript.startswith("Fehler"):
print("Ein Fehler ist aufgetreten:")
print(title)
print(transcript)
return
filename = save_to_file(video_url, title, transcript)
print(f"Transkript wurde in '{filename}' gespeichert.")
if __name__ == "__main__":
main()
In der Zeile 44 ist gleich der Prompt festgelegt, so dass du noch nicht einmal ChatGPT oder Grok mitteilen musst, was die KI mit dem Text machen soll. Du kannst den Prompt nach deinen Wünschen anpassen. 1500 Wörter ergeben etwa drei Seiten. Im vorliegenden Skript lautet der Prompt
"Bitte fasse das Transkript in einem Stück auf etwa 1500 Wörter zusammen und wähle als Überschrift die des Youtube-Videos und füge unter die Überschrift die URL des Youtube-Videos hinzu. Erzeuge die Zusammenfassung immer in deutscher Sprache."
Du bekommst also die Zusammenfassungen immer in deutscher Sprache. Dabei spielt es fast keine Rolle in welcher Sprache das Video verfasst ist. Vielleicht findest du einen noch besseren Prompt. Willkommen in einer neuen Welt!
Warum dieses Tool? Es ist benutzerfreundlich, erfordert kein technisches Vorwissen und verwandelt zeitintensive Videorecherche in einen effizienten Workflow. Ob für Bildung, Arbeit oder persönliche Projekte – der YouTube Transkript Extractor spart dir Zeit und Mühe. Probier es aus und entdecke, wie einfach es ist, Inhalte zu meistern!
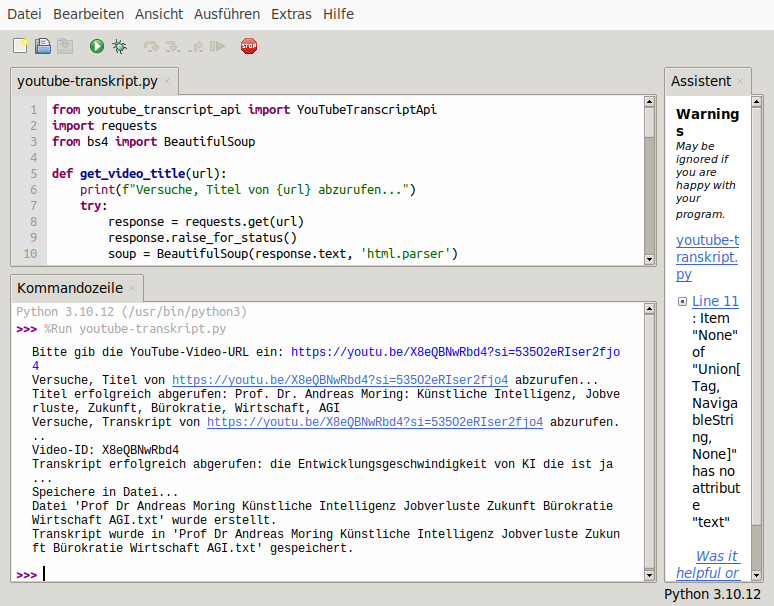
Ich habe das Verfahren unter Linux (Ubuntu) getestet. Python läuft aber auch unter Windows. Allerdings muss man einen Python-Interpreter herunterladen und konfigurieren. Anleitungen gibt es Internet.
Python-Skript mit grafischer Oberfläche: Entwurf von Grok3. Die Farben kann man selbst abändern lassen. Das Skript macht das selbe in grün – nur eben mit einer Oberfläche. Man kann daraus auch eine EXE-Datei für Windows erstellen, was ich später noch vorhaben.
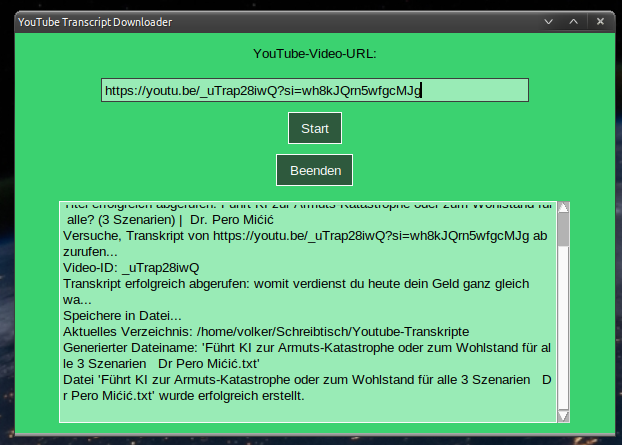
Die Textdatei landet im selben Ordner, in dem sich das Skript befindet. Hier das Skript:
from youtube_transcript_api import YouTubeTranscriptApi
import requests
from bs4 import BeautifulSoup
import tkinter as tk
from tkinter import scrolledtext, messagebox
import threading
import os
# Arbeitsverzeichnis auf das Skript-Verzeichnis setzen
script_dir = os.path.dirname(os.path.abspath(__file__))
os.chdir(script_dir)
def get_video_title(url):
log("Versuche, Titel von {} abzurufen...".format(url))
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text.replace(' - YouTube', '').strip()
log("Titel erfolgreich abgerufen: {}".format(title))
return title
except Exception as e:
error_msg = "Fehler beim Abrufen des Titels: {}".format(str(e))
log(error_msg)
return error_msg
def get_transcript(video_url):
log("Versuche, Transkript von {} abzurufen...".format(video_url))
try:
if 'youtube.com/watch?v=' in video_url:
video_id = video_url.split('watch?v=')[1].split('&')[0]
elif 'youtu.be/' in video_url:
video_id = video_url.split('youtu.be/')[1].split('?')[0]
elif 'youtube.com/live/' in video_url:
video_id = video_url.split('live/')[1].split('?')[0]
else:
error_msg = "Ungültige YouTube-URL"
log(error_msg)
return error_msg
log("Video-ID: {}".format(video_id))
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['de', 'en'])
full_transcript = " ".join(entry['text'] for entry in transcript)
log("Transkript erfolgreich abgerufen: {}...".format(full_transcript[:50]))
return full_transcript
except Exception as e:
error_msg = "Fehler beim Abrufen des Transkripts: {}".format(str(e))
log(error_msg)
return error_msg
def save_to_file(url, title, transcript):
log("Speichere in Datei...")
log("Aktuelles Verzeichnis: {}".format(os.getcwd()))
filename = "".join(c for c in title if c.isalnum() or c in " -_") + ".txt"
log("Generierter Dateiname: '{}'".format(filename))
content = f"Titel: {title}\nURL: {url}\n\nTranskript:\n{transcript}\n\n"
content += "Bitte fasse das Transkript in einem Stück auf etwa 2000 Wörter zusammen und wähle als Überschrift die des Youtube-Videos und füge unter die Überschrift die URL des Youtube-Videos hinzu. Falls das Transkript in einer Fremdsprache besteht, verfasse die Zusammenfassung auf Deutsch. Bitte schaffe auch einen Absatz als Eingangsteil einer Kurzzusammenfassung und Inhaltsbeschreibung von etwa 300 Wörtern, der einen Themenüberblick liefert und die wichtigsten Kernaussagen zusammenfasst."
try:
with open(filename, 'w', encoding='utf-8') as file:
file.write(content)
log("Datei '{}' wurde erfolgreich erstellt.".format(filename))
except Exception as e:
log("Fehler beim Speichern der Datei: {}".format(str(e)))
return None
return filename
def log(message):
text_output.insert(tk.END, message + "\n")
text_output.see(tk.END)
root.update()
def process_video():
video_url = url_entry.get().strip()
if not video_url:
messagebox.showerror("Fehler", "Bitte gib eine YouTube-URL ein!")
return
title = get_video_title(video_url)
if title.startswith("Fehler"):
messagebox.showerror("Fehler", title)
return
transcript = get_transcript(video_url)
if transcript.startswith("Fehler"):
messagebox.showerror("Fehler", transcript)
return
filename = save_to_file(video_url, title, transcript)
if filename:
messagebox.showinfo("Erfolg", "Transkript wurde in '{}' gespeichert.".format(filename))
else:
messagebox.showerror("Fehler", "Datei konnte nicht gespeichert werden.")
def start_processing():
threading.Thread(target=process_video, daemon=True).start()
def on_button_hover(event, button, original_bg, hover_bg):
button.config(bg=hover_bg)
def on_button_leave(event, button, original_bg, hover_bg):
button.config(bg=original_bg)
# GUI Setup
root = tk.Tk()
root.title("YouTube Transcript Downloader")
root.geometry("600x400")
root.configure(bg="#3bd270") # Hintergrundfarbe geändert
# Schriftart definieren
font_style = ("Arial", 10)
# URL Eingabefeld
label = tk.Label(root, text="YouTube-Video-URL:", bg="#3bd270", fg="#000000", font=font_style)
label.pack(pady=10)
url_entry = tk.Entry(root, width=60, bg="#99ebb6", fg="#000000", font=font_style, relief="flat", borderwidth=2)
url_entry.pack(pady=5)
# Buttons
start_button = tk.Button(root, text="Start", command=start_processing, bg="#2e593d", fg="#FFFFFF", font=font_style, relief="flat", padx=10, pady=5)
start_button.pack(pady=5)
start_button.bind("<Enter>", lambda e: on_button_hover(e, start_button, "#2e593d", "#1e392d"))
start_button.bind("<Leave>", lambda e: on_button_leave(e, start_button, "#2e593d", "#1e392d"))
quit_button = tk.Button(root, text="Beenden", command=root.quit, bg="#2e593d", fg="#FFFFFF", font=font_style, relief="flat", padx=10, pady=5)
quit_button.pack(pady=5)
quit_button.bind("<Enter>", lambda e: on_button_hover(e, quit_button, "#2e593d", "#1e392d"))
quit_button.bind("<Leave>", lambda e: on_button_leave(e, quit_button, "#2e593d", "#1e392d"))
# Textausgabe
text_output = scrolledtext.ScrolledText(root, width=70, height=20, bg="#99ebb6", fg="#000000", font=font_style, relief="flat", borderwidth=2)
text_output.pack(pady=10)
root.mainloop()
Keine Lust zum Lesen? Das nachfolgende Programm wandelt den Text, der in einer text.txt steht in Sounddateien um. Das Python-Skript erzeugt eine mp3. und eine wav-Datei. Die text.txt muss sich im selben Ordner wie das Python-Skript befinden. Die Umwandlung erfolgt mit Google Text to Speech.
from gtts import gTTS
import os
import re
def clean_text(text):
"""Entfernt Sonderzeichen, Bindestriche, Gänsefüßchen und Smileys aus dem Text."""
invalid_chars = r"[\"'“”‘’`´…\-–—:;(){}\[\]<>|@#$%^&*_+=/\\😊😂👍]"
cleaned_text = re.sub(invalid_chars, ' ', text)
return cleaned_text
def text_to_speech(input_file="text.txt", lang="de", output_mp3="output.mp3", output_wav="output.wav"):
"""Liest den Text aus einer Datei, bereinigt ihn und wandelt ihn in Sprache um."""
try:
if not os.path.exists(input_file):
print(f"Error: {input_file} not found.")
return None, None
with open(input_file, "r", encoding="utf-8") as file:
text = file.read().strip()
text = clean_text(text)
if not text:
print("Error: The text file is empty after cleaning.")
return None, None
tts = gTTS(text=text, lang=lang)
# Save as MP3
tts.save(output_mp3)
print(f"MP3 file saved as: {output_mp3}")
# Convert MP3 to WAV (requires ffmpeg installed)
os.system(f"ffmpeg -i {output_mp3} -ar 8000 -ac 1 -y {output_wav}")
print(f"WAV file saved as: {output_wav}")
return output_mp3, output_wav
except Exception as e:
print(f"Error during text-to-speech conversion: {e}")
return None, None
def main():
"""Führt die Sprachsynthese mit einer Textdatei aus."""
text_to_speech()
if __name__ == "__main__":
main()
Falls eine Fehlermeldung kommt, musst du wahrscheinlich laut Hinweis mit pip die notwendigen Python-Bibliotheken installieren. Wahrscheinlich musst du nur gTTS installieren:
pip install gTTS
Die Text-to-Speech-API Google gTTS ist kostenlos und erfordert keine Anmeldung. Dafür klingt die weibliche Stimme etwas zu monoton. Oft ist die Betonung unnatürlich. Ich finde den Text zu langsam aufgesagt. Spielt man die Audiodateien mit VLC ab, lässt sich die Geschwindigkeit einstellen. Lesen geht schneller oder der Sinn lässt sich durch Lesen besser erfassen.
Beta-Version für Windows: Läuft bei mir auf Window 7 mit 32 Bit. Auf Windows 10 und 11 wird es aller wahrscheinlich nach nicht funktionieren, da Zertifikate fehlen und Windows glaubt es würde sich um Viren handeln. In der nachfolgenden Zip-Datei sind die Windows-EXE, der Quellcode und weitere Tipps:
Python-Windows-Youtube-Zusammenfassungen.zip
Damit das Python-Skript auf Windows läuft, musst es noch angepasst werden, damit die erzeugten Textdateien auf dem Desktop abgelegt werden und nicht versteckt in einem temp-Ordner:
from youtube_transcript_api import YouTubeTranscriptApi
import requests
from bs4 import BeautifulSoup
import tkinter as tk
from tkinter import scrolledtext, messagebox
import threading
import os
# Arbeitsverzeichnis auf das Skript-Verzeichnis setzen
script_dir = os.path.dirname(os.path.abspath(__file__))
os.chdir(script_dir)
def get_video_title(url):
log("Versuche, Titel von {} abzurufen...".format(url))
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text.replace(' - YouTube', '').strip()
log("Titel erfolgreich abgerufen: {}".format(title))
return title
except Exception as e:
error_msg = "Fehler beim Abrufen des Titels: {}".format(str(e))
log(error_msg)
return error_msg
def get_transcript(video_url):
log("Versuche, Transkript von {} abzurufen...".format(video_url))
try:
if 'youtube.com/watch?v=' in video_url:
video_id = video_url.split('watch?v=')[1].split('&')[0]
elif 'youtu.be/' in video_url:
video_id = video_url.split('youtu.be/')[1].split('?')[0]
elif 'youtube.com/live/' in video_url:
video_id = video_url.split('live/')[1].split('?')[0]
else:
error_msg = "Ungültige YouTube-URL"
log(error_msg)
return error_msg
log("Video-ID: {}".format(video_id))
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=['de', 'en'])
full_transcript = " ".join(entry['text'] for entry in transcript)
log("Transkript erfolgreich abgerufen: {}...".format(full_transcript[:50]))
return full_transcript
except Exception as e:
error_msg = "Fehler beim Abrufen des Transkripts: {}".format(str(e))
log(error_msg)
return error_msg
def save_to_file(url, title, transcript):
log("Speichere in Datei...")
log("Aktuelles Verzeichnis: {}".format(os.getcwd()))
filename = "".join(c for c in title if c.isalnum() or c in " -_") + ".txt"
log("Generierter Dateiname: '{}'".format(filename))
# Desktop Pfad auf Windows
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop", filename)
content = f"Titel: {title}\nURL: {url}\n\nTranskript:\n{transcript}\n\n"
content += "Bitte fasse das Transkript in einem Stück auf etwa 2000 Wörter zusammen und wähle als Überschrift die des Youtube-Videos und füge unter die Überschrift die URL des Youtube-Videos hinzu. Falls das Transkript in einer Fremdsprache besteht, verfasse die Zusammenfassung auf Deutsch. Bitte schaffe auch einen Absatz als Eingangsteil einer Kurzzusammenfassung und Inhaltsbeschreibung von etwa 300 Wörtern, der einen Themenüberblick liefert und die wichtigsten Kernaussagen zusammenfasst."
try:
with open(desktop_path, 'w', encoding='utf-8') as file:
file.write(content)
log("Datei '{}' wurde erfolgreich erstellt.".format(desktop_path))
except Exception as e:
log("Fehler beim Speichern der Datei: {}".format(str(e)))
return None
return desktop_path
def log(message):
text_output.insert(tk.END, message + "\n")
text_output.see(tk.END)
root.update()
def process_video():
video_url = url_entry.get().strip()
if not video_url:
messagebox.showerror("Fehler", "Bitte gib eine YouTube-URL ein!")
return
title = get_video_title(video_url)
if title.startswith("Fehler"):
messagebox.showerror("Fehler", title)
return
transcript = get_transcript(video_url)
if transcript.startswith("Fehler"):
messagebox.showerror("Fehler", transcript)
return
filename = save_to_file(video_url, title, transcript)
if filename:
messagebox.showinfo("Erfolg", "Transkript wurde in '{}' gespeichert.".format(filename))
else:
messagebox.showerror("Fehler", "Datei konnte nicht gespeichert werden.")
def start_processing():
threading.Thread(target=process_video, daemon=True).start()
def on_button_hover(event, button, original_bg, hover_bg):
button.config(bg=hover_bg)
def on_button_leave(event, button, original_bg, hover_bg):
button.config(bg=original_bg)
# GUI Setup
root = tk.Tk()
root.title("YouTube Transcript Downloader")
root.geometry("600x400")
root.configure(bg="#A9B4C2") # Blaugrauer Hintergrund
# Schriftart definieren
font_style = ("Arial", 10)
# URL Eingabefeld
label = tk.Label(root, text="YouTube-Video-URL:", bg="#A9B4C2", fg="#000000", font=font_style)
label.pack(pady=10)
url_entry = tk.Entry(root, width=60, bg="#B9C6D3", fg="#000000", font=font_style, relief="flat", borderwidth=2)
url_entry.pack(pady=5)
# Buttons
start_button = tk.Button(root, text="Start", command=start_processing, bg="#3D5A6C", fg="#FFFFFF", font=font_style, relief="flat", padx=10, pady=5)
start_button.pack(pady=5)
start_button.bind("<Enter>", lambda e: on_button_hover(e, start_button, "#3D5A6C", "#2F4755"))
start_button.bind("<Leave>", lambda e: on_button_leave(e, start_button, "#3D5A6C", "#2F4755"))
quit_button = tk.Button(root, text="Beenden", command=root.quit, bg="#3D5A6C", fg="#FFFFFF", font=font_style, relief="flat", padx=10, pady=5)
quit_button.pack(pady=5)
quit_button.bind("<Enter>", lambda e: on_button_hover(e, quit_button, "#3D5A6C", "#2F4755"))
quit_button.bind("<Leave>", lambda e: on_button_leave(e, quit_button, "#3D5A6C", "#2F4755"))
# Textausgabe
text_output = scrolledtext.ScrolledText(root, width=70, height=20, bg="#B9C6D3", fg="#000000", font=font_style, relief="flat", borderwidth=2)
text_output.pack(pady=10)
root.mainloop()
Was ist zu beachten, wenn ich meine Python-Skritpe für Windows selbst kompilieren möchte? https://grok.com/share/bGVnYWN5_e9f40763-cab6-4835-bfa3-48b535afd027
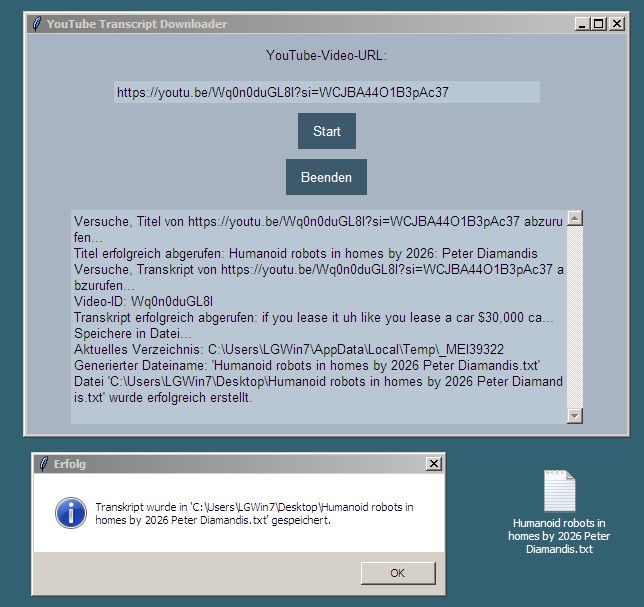
Zusammenfassung eines Video über die Zukunft humanoider Haushalts-Roboter als Beispiel: https://grok.com/share/bGVnYWN5_bbfb7c1e-dab8-4433-8a7b-07cae24923f6
Das Video als Beispiel: Das Interview ist auf Englisch. Aber mit Hilfe des Programms erhältst du schnell Zugang zu deutschsprachigen Zusammenfassungen und erhältst auf diese Weise einen Informationsvorsprung.
Für dieses Video über die Zukunft humanoider Haushalts-Roboter habe ich eine Zusammenfassung in deutscher Sprache erzeugen lassen. Dadurch habe ich mir viel Zeit erspart. Probiere es einfach selbst aus.